应用密码学概要
文章目录
异或(XOR)
文章的开篇,我们从最简单的异或说起。异或是一个二元判断操作,当两个输入相同时返回0,相异时返回0。常用符号”⊕”来表示。常见操作定义如下:
$$ 1 \bigoplus 1=0,0 \bigoplus 0=0,1 \bigoplus 0=1,0 \bigoplus 1=1 $$
除了以上定义,异或操作还具有如下属性:
- 顺序无关性:A⊕(B⊕C)=(A⊕B)⊕C
- 可交换:A⊕B=B⊕A
- 任何输入与自身异或,输出为0:A⊕A=0
- 任何输入与0异或,其结果为其本身:1⊕0=1,0⊕0=0
而基于以上四个属性,我们可以推导地五条重要的属性:a⊕b⊕a=b
A⊕B⊕A=A⊕A⊕B(属性1)
=0⊕B(属性3)
=B(属性4)
以上定义,除对“0”和“1”的异或操作满足外,可以推广到任何多个位的操作。如对两个数字或两个字符串进行按位异或操作,也均满足以上定义。
#定义字符串按位异或的操作
def sxor(a,b)
return ''.join(chr(ord(a) ^ ord(b)) for a,b in zip(s1,s2))
val=sxor('aa','bb')=> val:'\x03\x03'
sxor(val,'aa')=>'bb'
sxor(val,'bb')=>'aa'
一次性密码本(One-Time Pad)
基于以上关于异或的朴素定义,我们可以得到一个“坚不可摧”的加密方式,即:一次性密码本加密。
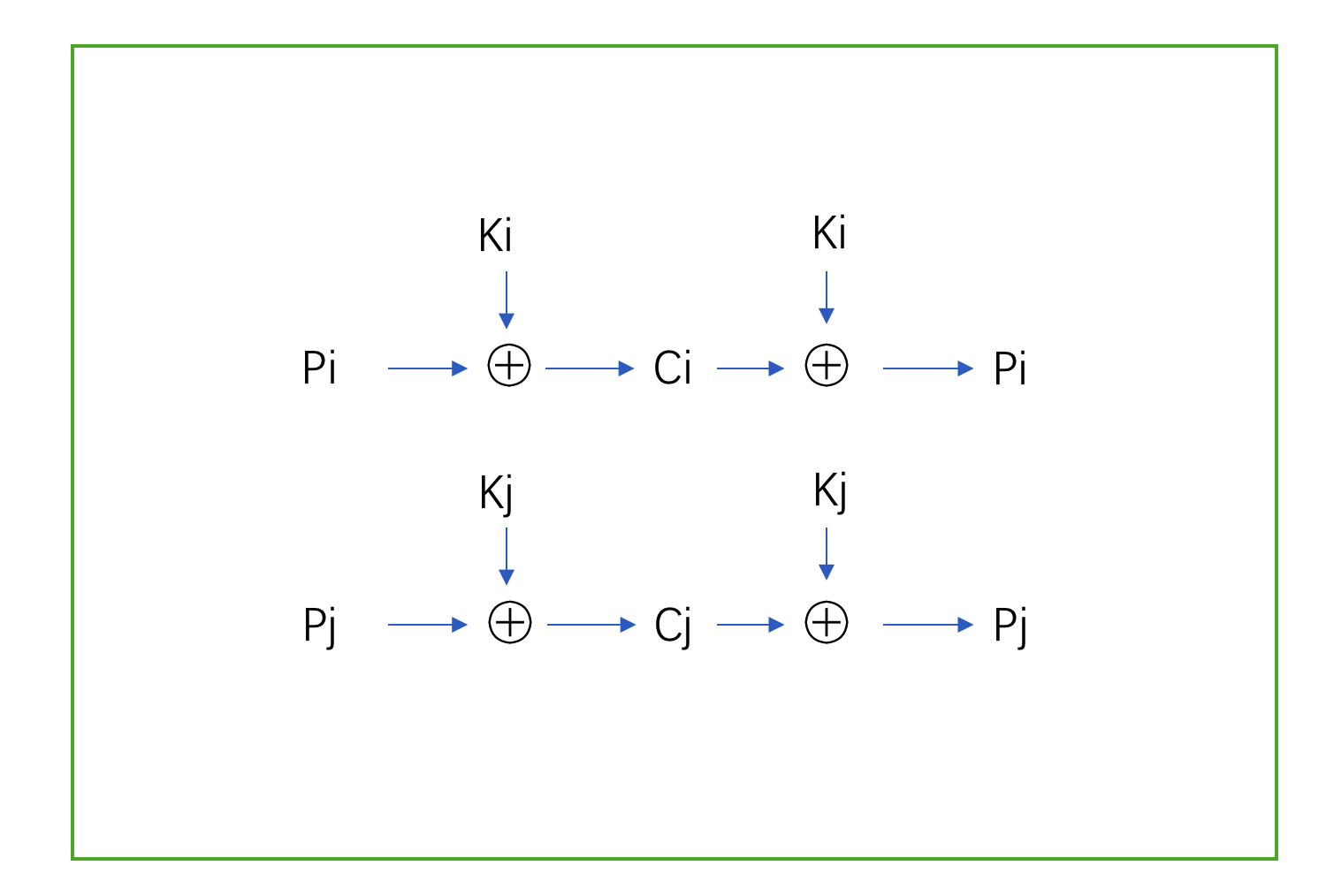
如上图所示,其中P代表明文(plaintext),C代表密文(ciphertext),K代表密钥(Key)。先通过对明文进行按位异或,将得到密文,完成加密。密文用相同的密钥进行按位异或,将得到明文信息,完成解密的操作。 从安全性上来看,攻击者知道密文C的情况下,可以证明其再没有K的信息时,他将不能获取任何关于明文的信息,但前提是:
- 密钥K必须完全随机
如果,密钥K不是完全随机产生,则无法证明其安全性。因为密钥不真随机的情况下,明文P与密文C可能存在一定的函数关系,而非完全独立,即使破解函数关系依旧非常困难,但是却不是可证明安全的。
密钥K不能复用
另外一个前提是密钥不能复用。假设攻击者获取了两份明文P1、P2经用同一密钥K加密而得到的密文C1和C2,攻击者只需要将两份密钥进行异或操作,即可得到明文的的异或结果。推导如下:
C1⊕C2=(P1⊕K)⊕(P2⊕K)
=P1⊕K⊕P2⊕K
=P1⊕P2⊕K⊕K)
=P1⊕P2
尽管得到的是P1、P2的异或结果,要独立分离出P1和P2的准确结果依旧困难,但要注意的是,两个明文的异或结果依旧会泄漏一些信息。如下面两张图片A、B进行异或,得到的结果几乎泄漏了所有信息。
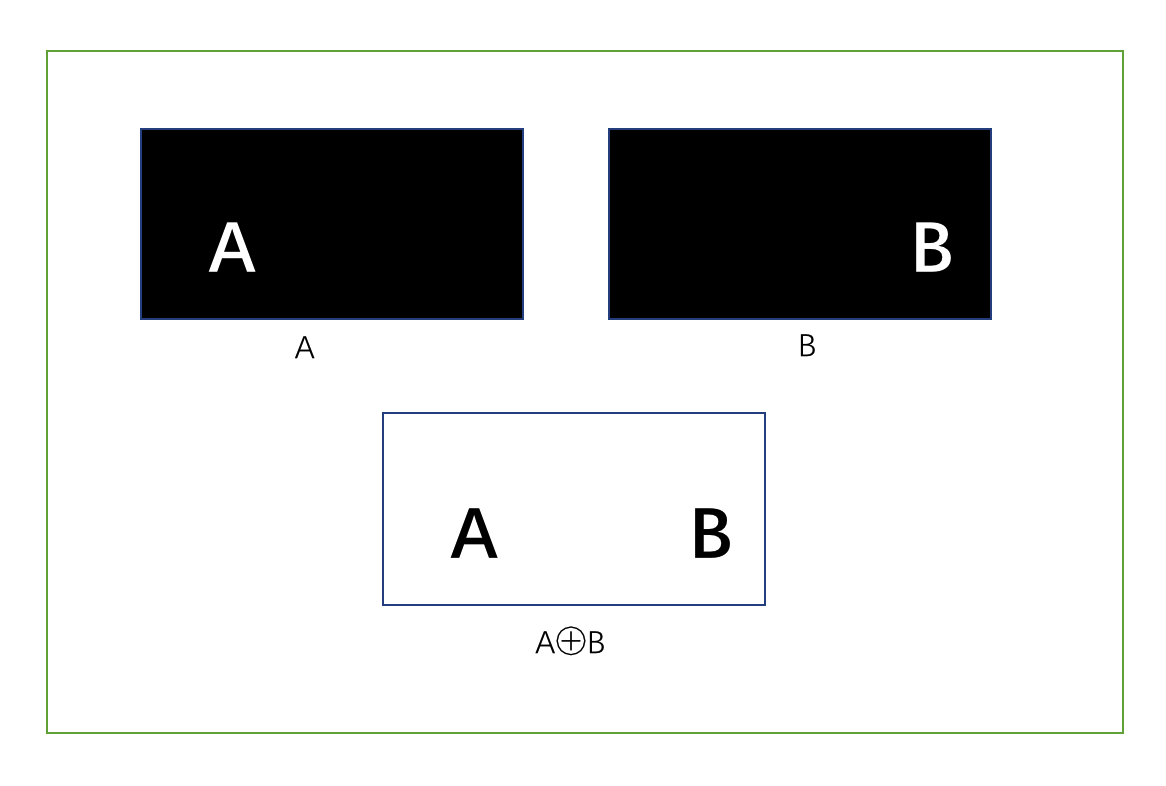
密钥序列不能重用,这意味着每个明文的位都必须有一个密钥位与其对应,即密钥长度与明文长度要一样,这一点在工程实践上是没有意义的,这也是一次性密码本(OTP)在实际中很少使用的原因。
DES与AES
前文说到一次性密码本,它需要一个与明文长度一样长的随机生成的密钥来完成加密和解密,这种要求在工程实践上难度很大,接下来我们介绍两个可以用固定长度密钥对明文分组进行加密的算法。
DES
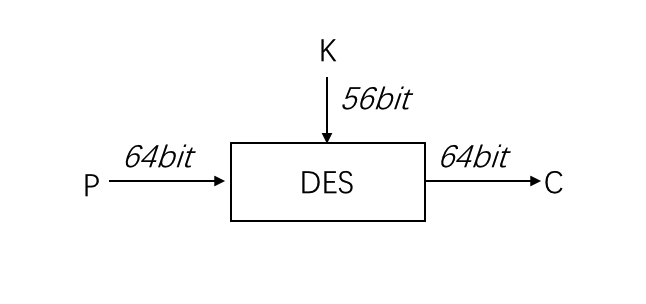
DES是一种用56位密钥对64位长的明文分组进行加密的方式。
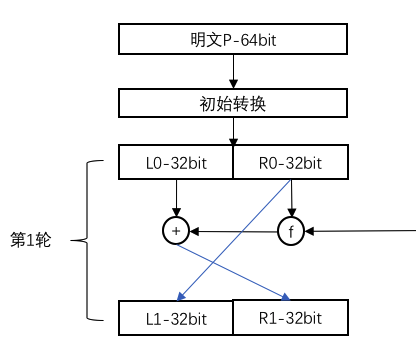
DES是一种对称加密,加密和解密都使用相同的密钥。它采取迭代算法来进行加密,每一次加密过程都包含16轮操作,而每一轮的操作完全相同。只是每一轮的操作会使用不同的子密钥进行,子密钥由主密钥推导而来,上一轮的输出为下一轮的输入,整个迭代加密结构被称为Feistel网络,Feistel网络结构如下:
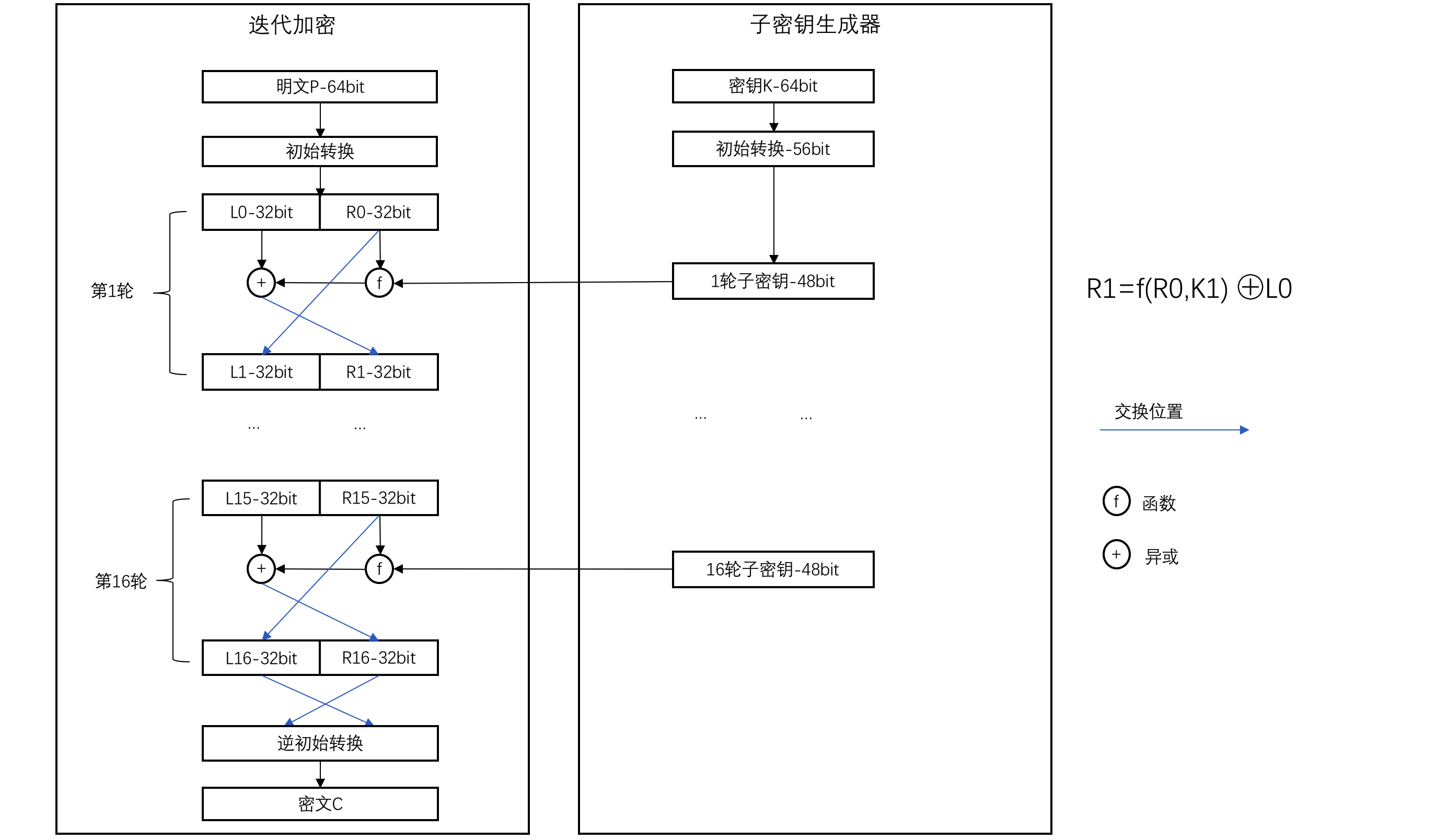
64位的明文在完成初始转换后,会被分割成L0与R0左右两部分,每部分长度为32位,右半部分与生成的子密钥作为参数传入f函数,f函数的输出与左部分异或后作为下一轮的右半部分,而右半部分将直接复制到下一轮的左半部分。即:
R1=f(R0,K1)⊕L0
L1=L0
可见DES的每一轮只对输入内容的左半部分加密,右半部分只是简单复制到下一轮。
初始置换:
关于初始转换,本身对加密安全性没有任何影响,其只是对输入内容进行按位的位置变变换,如将第1位放置30位,30位放到20位等,逆转换即为复位。为什么要这么做?目前没有得到可解释的理由。
f函数:
由上面流程可知,DES中,f函数在安全性上扮演着非常重要的角色。f函数包括以下几步处理:
位扩充
位扩充是指将32位的输入扩展为48位,使用查表的方式进行扩充,也称为E-盒转换。具体转换方式如下图所示。
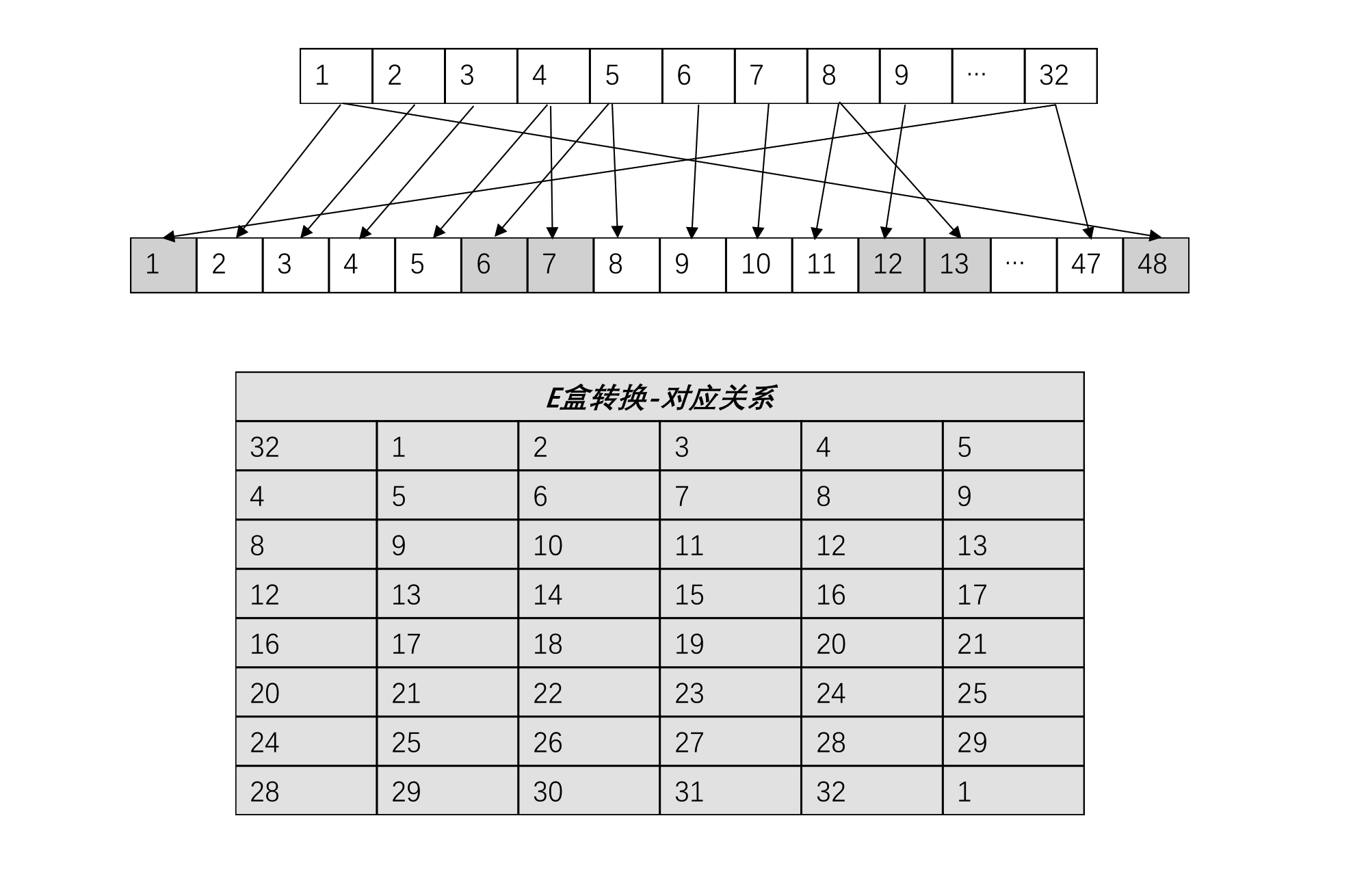
需要注意的是,E-盒为算法内的静态定义,每一次加密过程都用同一E-盒的定义进行扩充。从上图的扩充过程可知,32个输入位经过扩充后变为48位,其中正好有16个位出现了两次,如图中1号位、4号位、5号位等。但是E-盒保证了任意一个输入位都不会再同一个6位的输出分组中出现两次,如1号位出现在第一个6位分组和最后一个6位分组,4号位出现在第一个6位分组和第二个6位分组,这样做可以保证一半的输入位会影响两个不同的输出位置,而为什么以6个位作为分组单位?这与第三步的S-盒替换有关。
与子密钥K进行异或操作,这一步很简单,输入和子密钥长度都是48,按位异或即可。
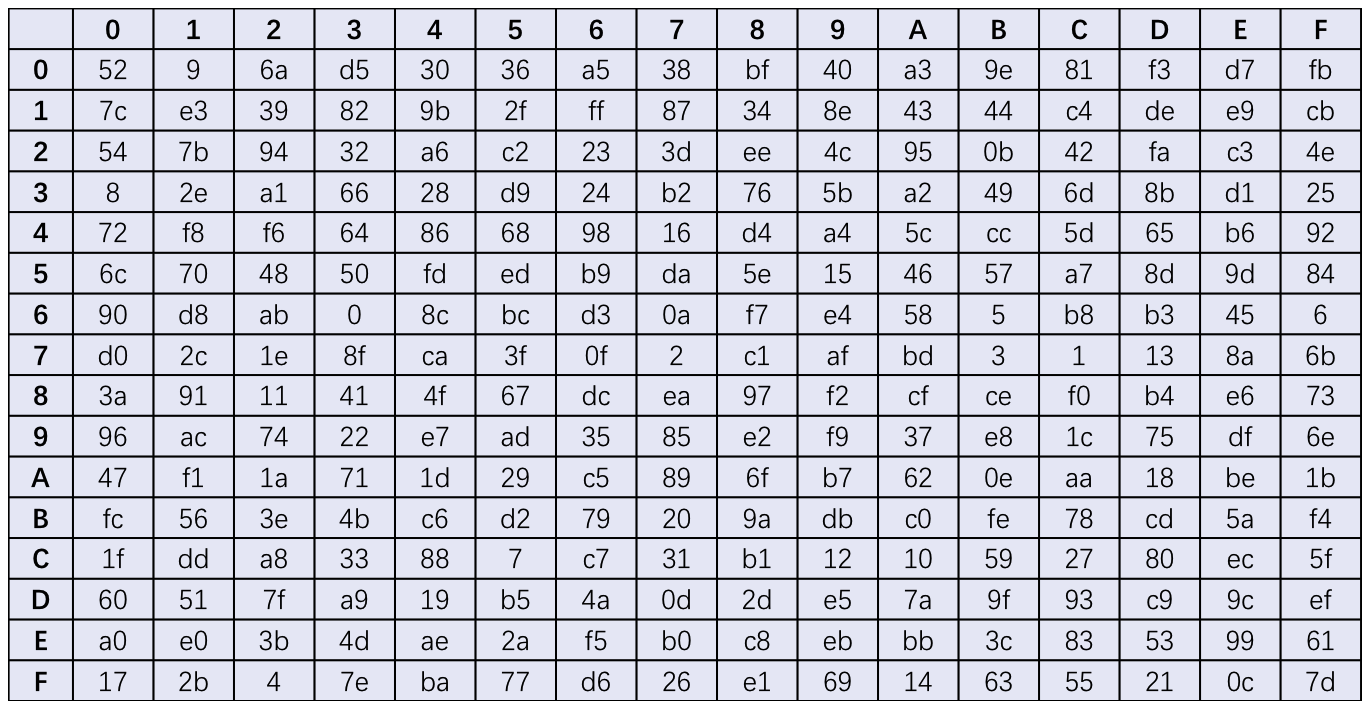
S-盒替换
经过前面两步,输入已经转换为48位,而最终的输出需要转换为32位,这是通过S-盒转换来完成的,它通过查表的方式将6位的输入映射为4位的输出。DES中定义了8个S-盒,每个S-盒包含2^6=64个4位的值(十进制:0-15),这64个值分为4行*16列的表格进行存储。按以下方式读取S-盒:
- 第一个6位分组读S-盒1、依次,第8个分组读S-盒8
- 每个6位分组的最高位盒最低位决定要读的行,中间四个位决定要读取的列
如下图,第五个6位分组的读取方式:
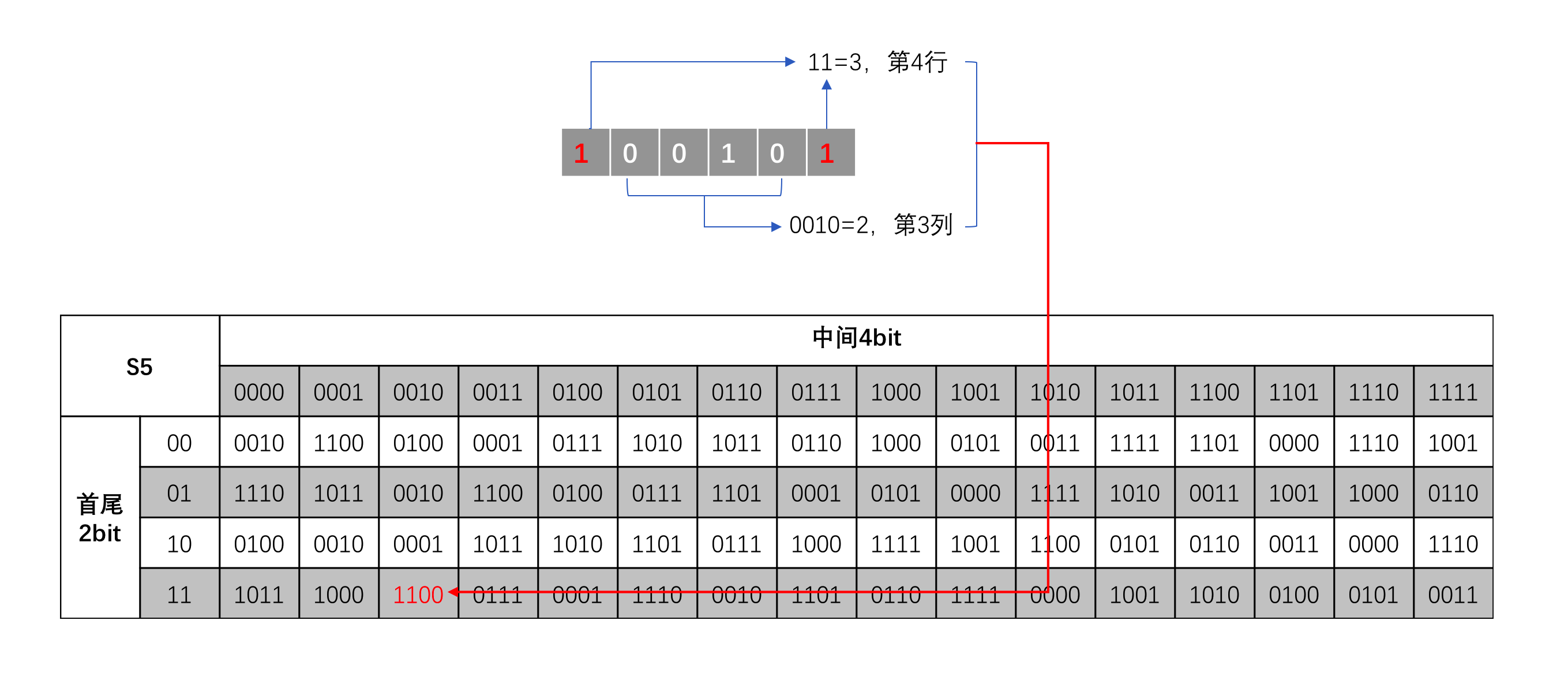
S-盒转换给DES算法带来了唯一的非线性转换,即满足:S(A)⊕S(B)!=S(A⊕B),它是DES加密过程中最重要的部分。
子密钥编排
DES的输入主密钥是64位的固定长度,而其中每第8个位为前面7个位的奇校验位,设置奇偶校验位除了能在密钥传输过程中用于检验密钥传输错误外,校验位的存在并没有增加密钥空间,对于增强加密安全性没有帮助。而密钥完整性校验,可以由更高级的办法进行,所以可以认为校验位的设置是一个比较过时的设计。
由于8位校验码的存在,所以DES其实是一个56位的主密钥加密,56位的主密钥在每一轮的加密过程中均会生成子密钥ki,而每一轮子密钥ki的长度固定是48位。子密钥生成算法如下图所示:
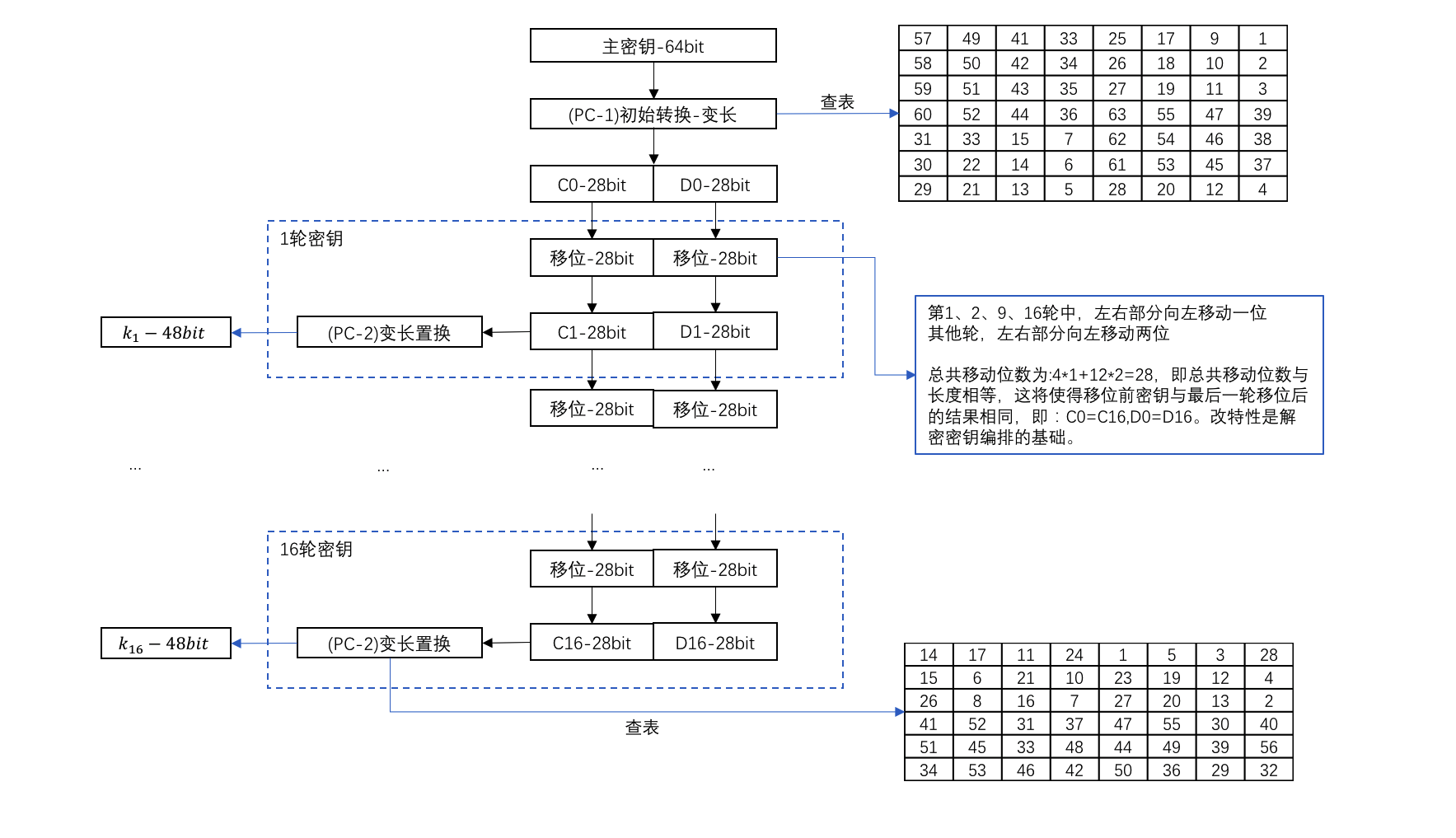
子密钥生成的算法里值得注意的是移位计算,移位计算会在左右两半部分同时进行,16轮密钥移动的位数正好为28位(左、右两半部分的长度),由此可得到移位前和16轮移位后的密钥后,结果是一样的。这为后续解密过程生成字密钥提供了可逆支持。
解密
DES的解密的重点是,解密算法与加密算法完全一致,这主要由密钥编排与Feistel网络的可逆性决定的。下面分别探讨密钥编排与Feistel网络的可逆性问题。
密钥编排可逆性
由上面子密钥的移位计算我们得到了移位前和16轮移位后的密钥完全一致,即C0=D16,D0=D16。而第16轮的,密钥由(C16,D16)进行PC-2转换得来。即:
k16=PC-2(C16,D16)
代入:C0=D16,D0=D16,得:
k16=PC-2(C0,D0)
(C0,D0)是由主密钥k进行PC-1转换而得来,所以:
k16=PC-2(PC-1(k))
即主密钥进行PC-1再进行PC-2,得到第16轮密钥k16。
k15由(C15,D15)进行PC-2转换而来,而(C15,D15)由(C16,D16)向右移位(移2位,记R2)而得到,即:
k15=PC-2(C15,D15)
=PC-2(R2(C16),R2(D16))
=PC-2(R2(C0),R2(D0))
同理可计算k1、k2…k14,只是向右移位的位数有所差异,第一轮不移位,第2、9、16轮右移一位,其他轮右移两位。
Feistel网络的可逆性
Feistel网络的一个重要特性是第一轮解密的结果是第16轮加密的逆,并可一次类推,第二轮的解密结果是第15轮加密的逆,直至最后一轮解密结果即为明文。 通过对比DES加密的第一轮和最后一轮
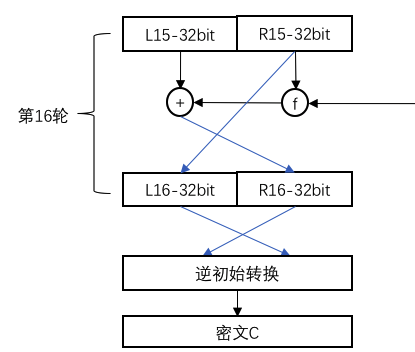
由第16轮加密过程可知,密文结果为第16轮加密后左右交换与逆初始转换后而来,所以,对密文进行初始转换(IP),即可得第16轮左右交换后的结果,因为初始转换与逆初始转换相互抵消,所以第一轮解密结果(DL0,DR0)为:
(DL0,DR0)=IP(C)=(R16,L16)
而L16由R15平移而来,所以:
DL0=R16
DR0=L16=R15
接着计算下一轮加密结果(DL1,DR1)
同理,DL1由DR0平移而来,所以
DL1=DR0=R15
根据算法计算DR1,
DR1=DL0⊕f(DR0,k16)= R16⊕f(L16,k16)
=[L15⊕f(R15,k16)]⊕f(R15,k16)
上式中,R15与f(R15,k16)进行了两次异或,由异或属性5(见上文,这一点非常重要,这一点的存在使得f函数的可逆性不是必须的,因为f函数里的S-盒变化是非线性不可逆的),得:
DR1=L15
以上推导即证明了第一轮解密后得到的记过与最后一轮加密前的结果是相等的,即第一轮解密的结果是最后一轮加密的逆。同理可推:
DL(i)=R(16-i)
DR(i)=L(16-i)
即:第i轮的解密结果,为第(16-i)轮的加密的逆,由此可知:最后一轮的解密结果即为(R0,L0),(R0,L0)进行左右变化和逆初始转换后即得到明文。
DES的安全性
说到DES的安全性,我们得先看看DES算法历史。
 (来源:wiki)
(来源:wiki)
由上述历史中可知,IBM和NSA共同设计了DES,但是对于密钥长度问题众说纷纭,到底是谁,为什么选择了56位的密钥没有定论。而56位位的密钥长度正是DES被认为不安全的主要原因,也就是说DES的不安全性不在其算法设计上,而在于其密钥长度过短,暴力破解的代价较小。
AES
从上述关于DES历史的引用中可以看出,DES的算法是IBM和NSA采取对外保密的方式进行设计的,许多关于算法设计上的选择原由,一直到后面才公开。而AES采取了完全相反的方式。1997年,NIST(美国国家标准与技术研究院)向社会公开征集新的高级密码标准(AES),并经过多轮评估竞选者提交的方案,最终于2001年确认宣布两位比利时密码学家设计的Rijndael方案成为新的高级密码标准。
AES在方案征集前确认了一下必须满足的要求:
- 分组加密,分组块大小固定为128位(关于分组加密的更多内容,见后文)。
- 支持三种密钥长度:128位、192位、256位。
- 不同于DES可以在硬件上可以高效实现,在软件上实现也应该可以高效。
Rijndael基本满足以上要求,主要区别是Rijndael的分组大小和密钥长度都可以为128、192和256,而AES只要求分组大小为128。即:
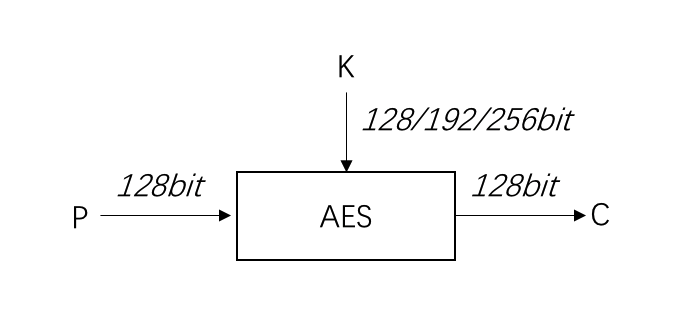
AES(Rijndael,下文所提AES均为Rijndael加密算法)算法加密过程如下图所示:
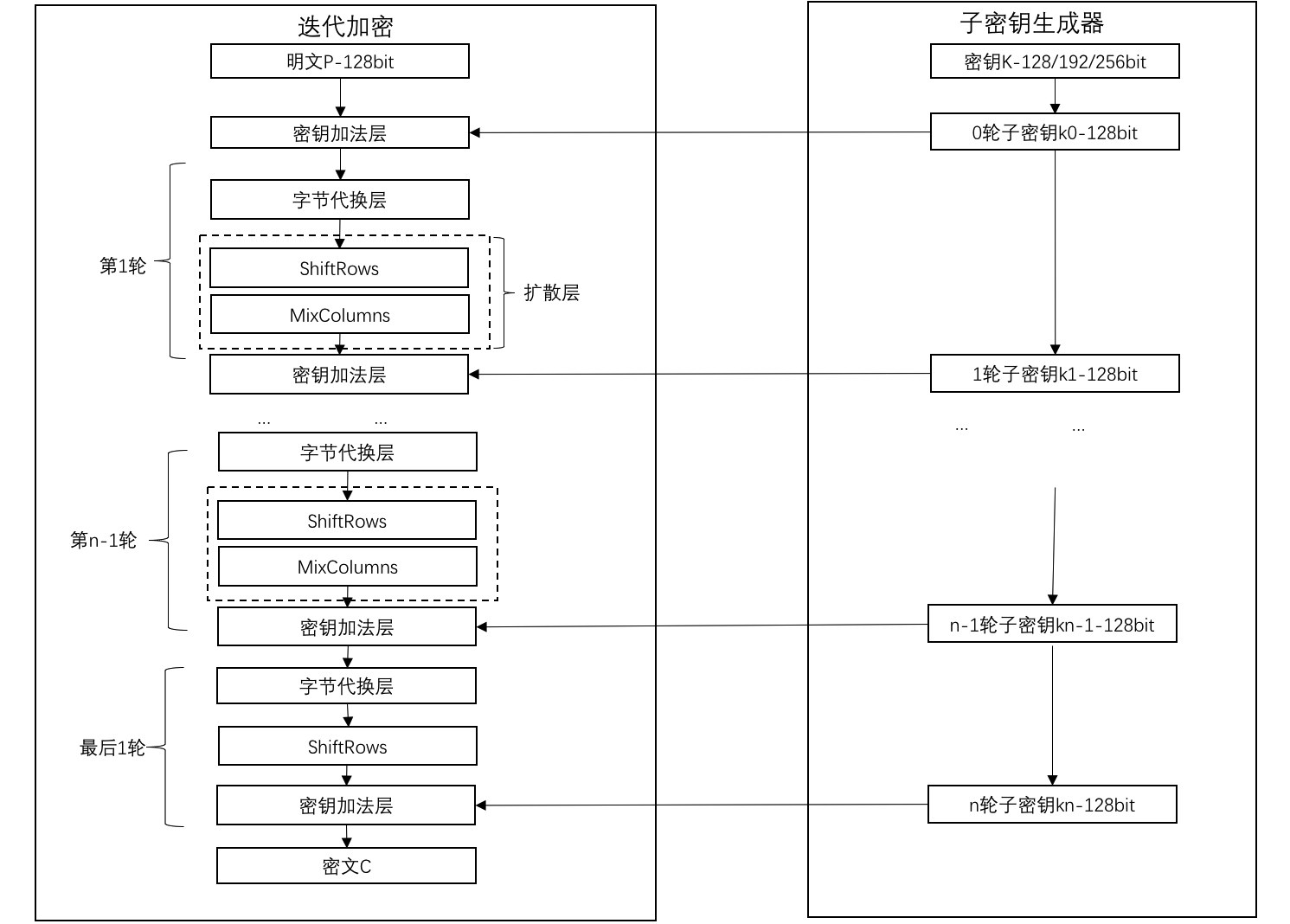
与DES一样,AES也采取多轮加密的方式,但是AES的加密轮数不是固定的,与密钥长度相关,128位长的密钥加密轮数是10轮,192位的密钥加密轮数是12轮,256位的密钥加密轮数是14轮。但是AES不具有Feistel网络结构,即加密解密的算法是不一样的,其中每一步都必须可以求逆运算来解密。同时AES每轮爹地啊,会加密整个分组(128位),而DES只加密分组的一半,即32位。
AES的每一轮需要经过字节代换层、扩散层(ShiftRows&MixColumns)、密钥加法层三层操作,但最后一层不会进行MixColumns的操作,在第一轮开始前需要也需要进行一次密钥加法层的操作。
密钥加法层
AES的密钥加法层很简单,子密钥生成器每一轮都会根据主密钥编排生成一个128位的子密钥。子密钥与当前状态的数据进行异或即为密钥加法层的输出。由此可见,无论前文的DES,还是AES,密钥在加密算法中都只与加密内容进行异或运算,并不会有其他复杂的算法。
字节代换层
与DES类似,AES在字节代换层,提供了非线性变换的S-盒子替换,提供了AES加密过程的唯一非线性元素。但AES的S-盒是一个双向映射,这是解密操作所需要的。AES的S-盒是一个256位*8位的固定项对应表,AES每8位进行查表后替换。S-盒如下图所示:
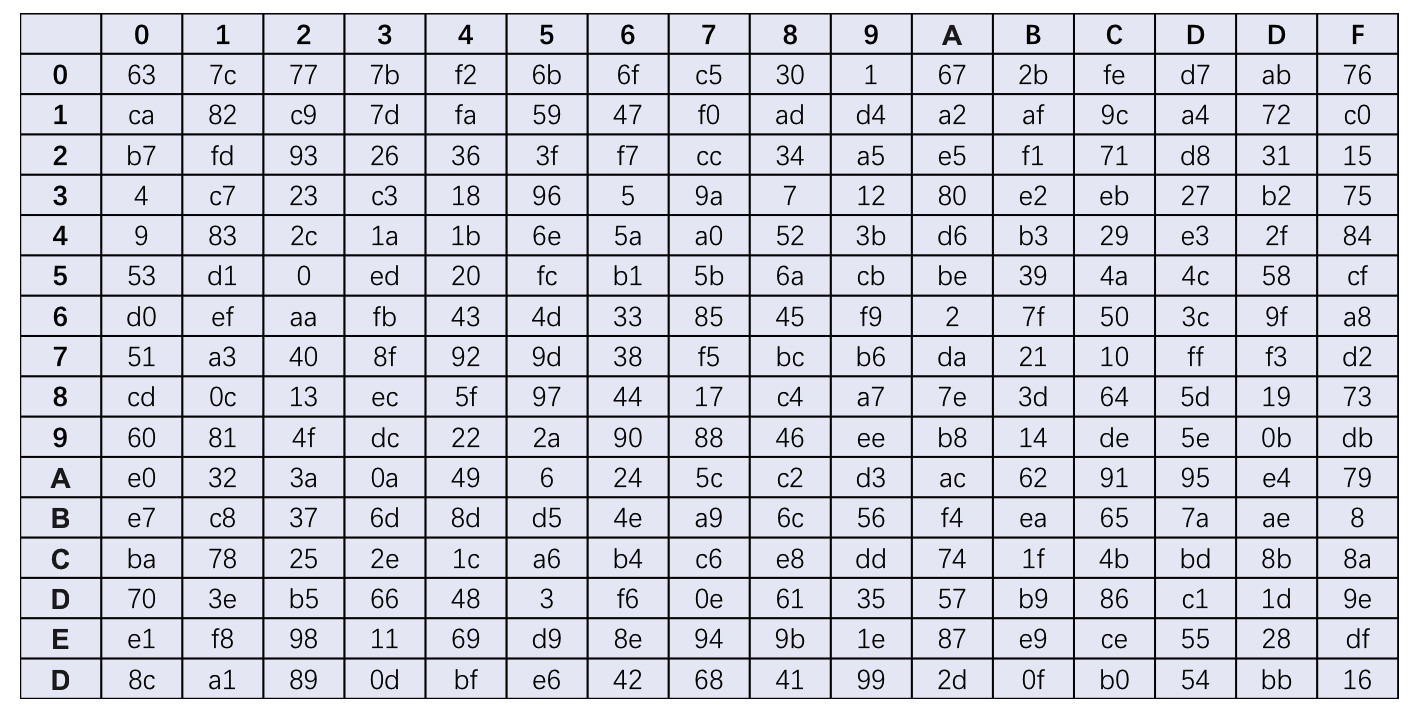
查表举例:
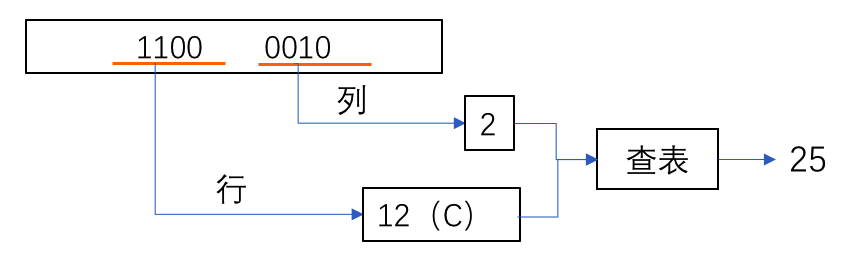
扩散层
在加密过程中设置扩散层是位了将一个明文位变化的影响扩散到多个密文的位置,以达到隐藏明文统计属性的目的。在AES中的扩散层主要两个操作:ShitRows(行移位)、MixColumns(列混淆),这两个操作均为线性操作,即满足:OP(A)+OP(B)=OP(A+B)。
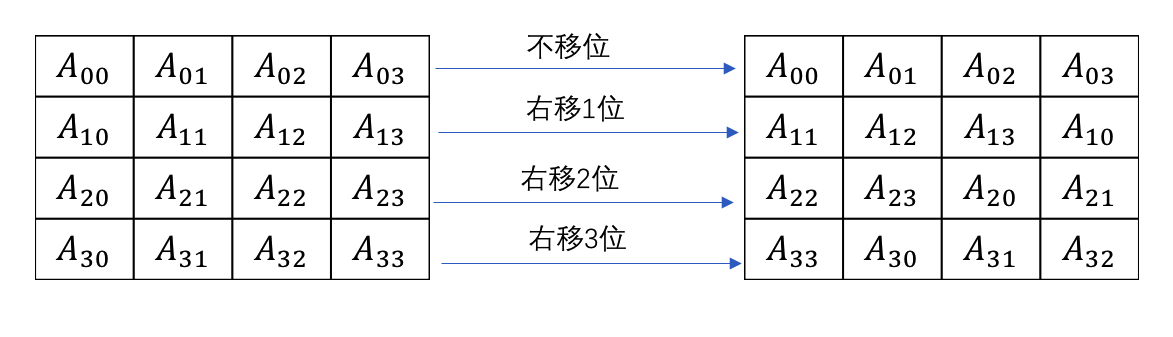
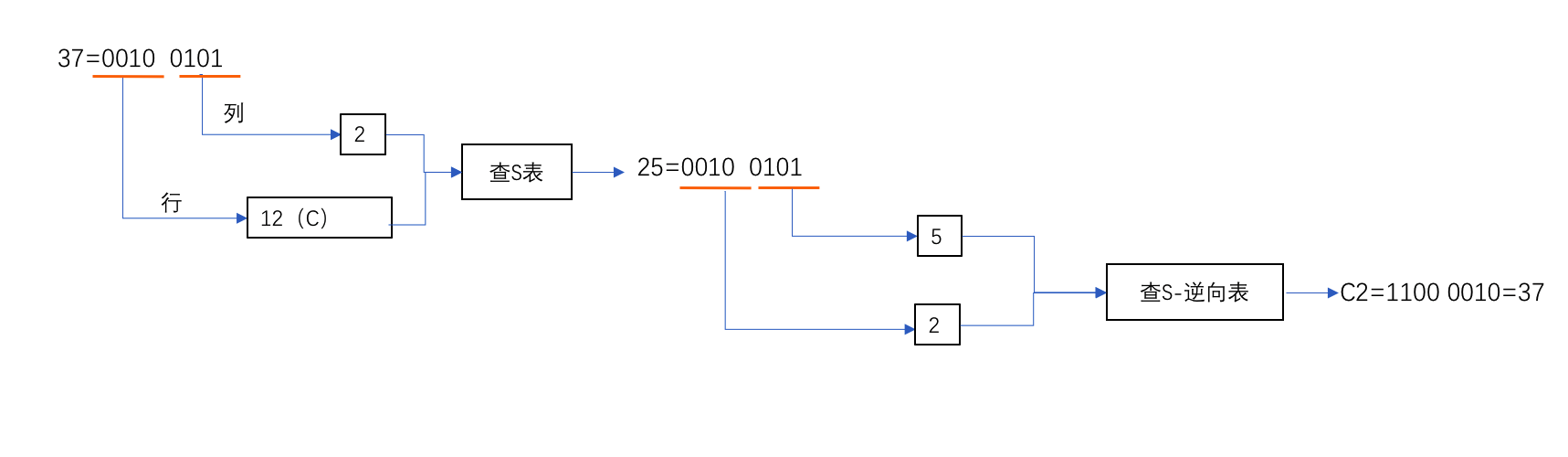
ShiftRows操作
在进行ShiftRows操作之前,需要将进行操作的输入分组划分为一个矩阵4*4的矩阵,矩阵中每个元素长度为一个字节(8bit,即128=4*4*8),然后对矩阵的每一行进行位移。具体算法如下所示:
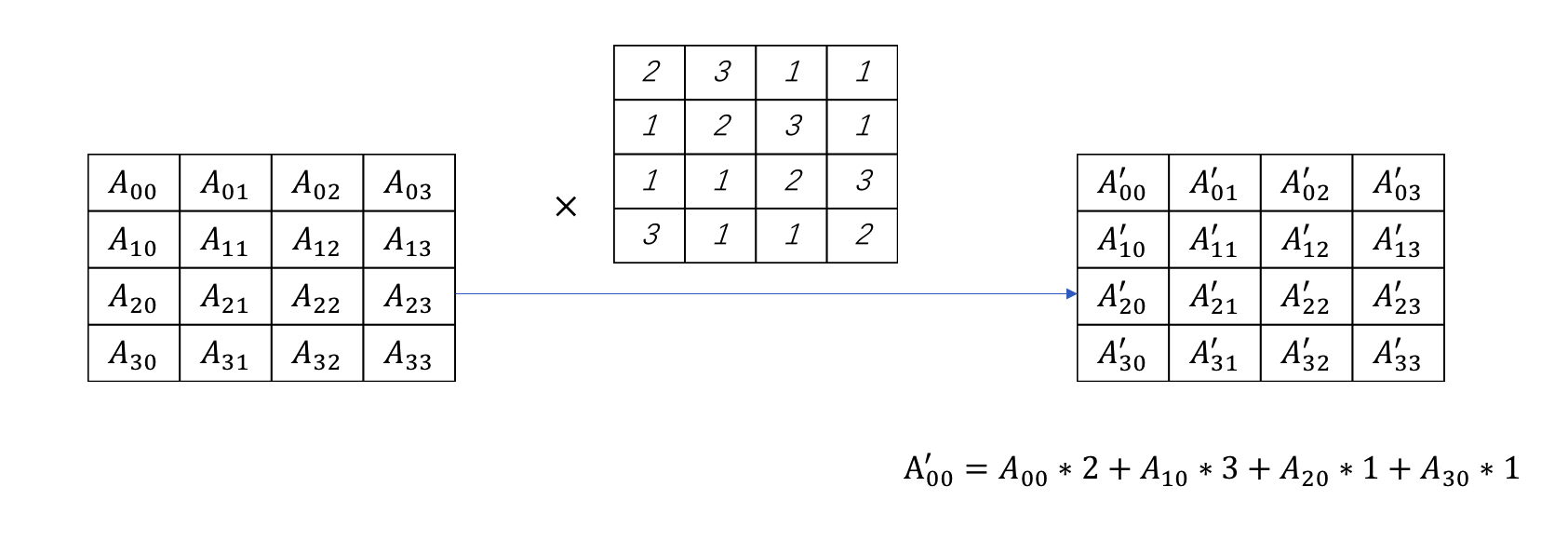
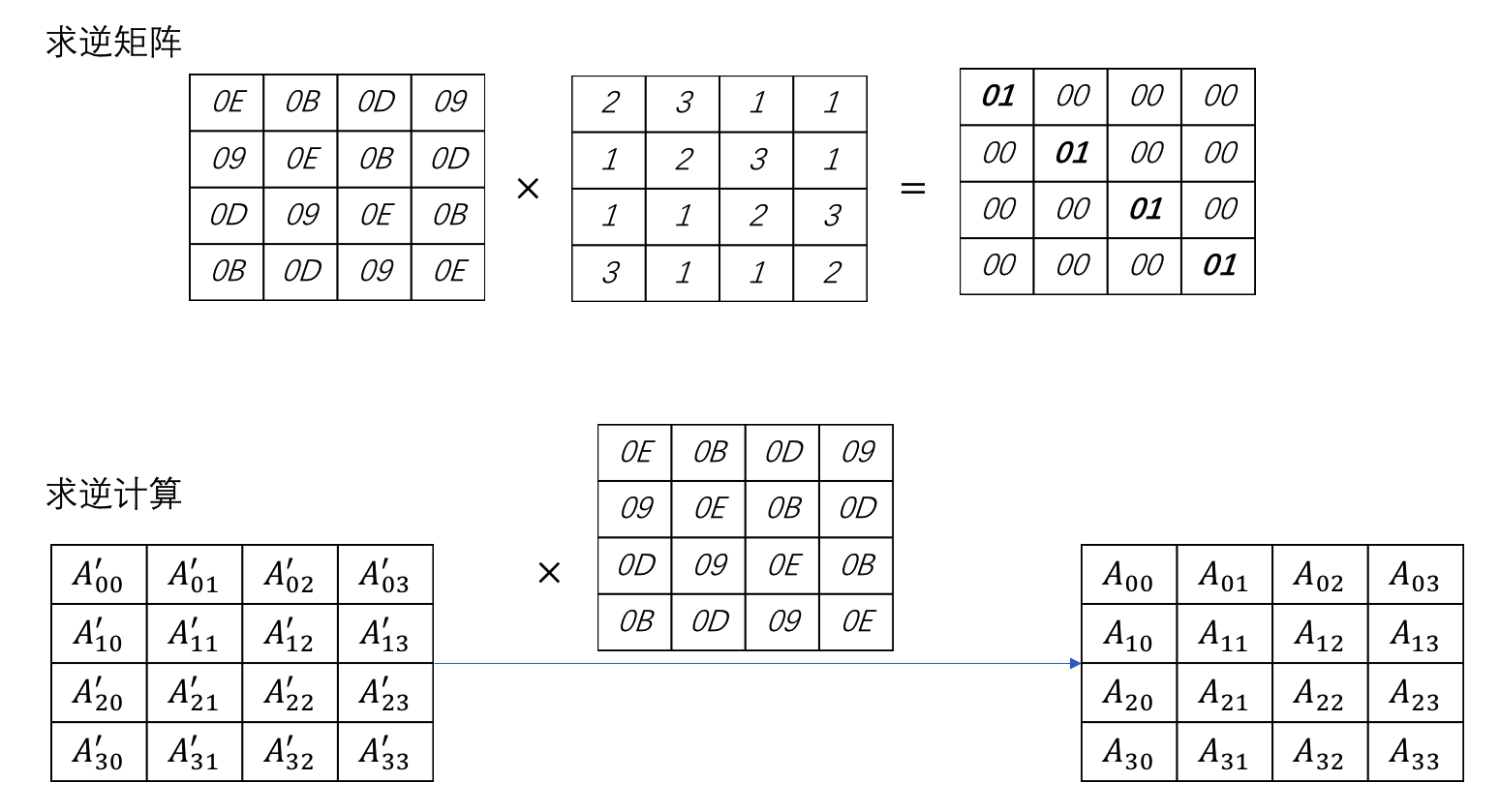
MixColumns操作
MixColumn操作采取对ShiftRows后的矩阵的与一个固定矩阵进行相乘(矩阵相乘)后得到。
子密钥编排
AES的子密钥编排,以原始主密钥(长度为128位、192位或156位)为输入,输出固定长度为128位,子密钥的个数等于加密轮数加1,因为在第一轮加密前需要进行一次密钥加法层的操作。即:128位的主密钥,加密轮数是10轮,共生成11个子密钥,192位的主密钥,加密轮数是12轮,共生成13个子密钥,256位的主密钥,加密轮数是14轮,共生成15个子密钥。
以128位主密钥生成为例,流程如下:
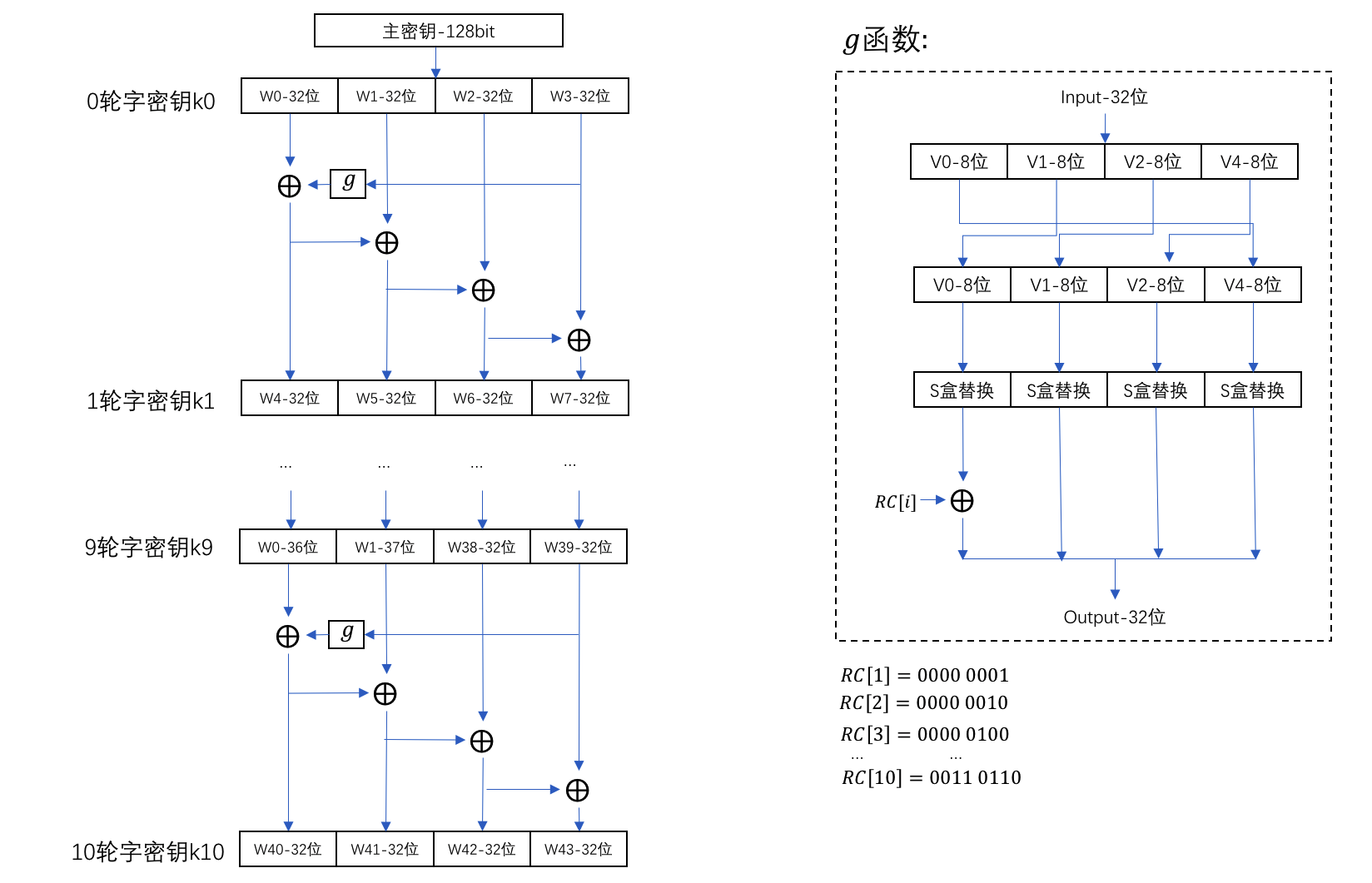
128位主密钥的AES需要11个子密钥,用元素长度为44的32位的数组来存储,表示为W0…W43,数组中的每一个元素经过如图中所示计算过程来生成,最终每4个元素组成一个子密钥,子密钥长度也正好为128位。即:
K0=(W0,W1,W2,W3)
K1=(W4,W5,W6,W7)
...
K10=(W40,W41,W42,W43)
与之类似,192位主密钥的AES需要的13个字密钥用W0…W51的52个元素来存储,256位主密钥的AES需要的15个字密钥用W0…W59的60个元素来存储,也是每4个元素组成一个128位的子密钥。
由上述可知,不同的主密钥长度,只是影响了加密轮数,而每一轮参与加密的子密钥长度是一致的,都是128位。
从实现上来并不约束是一次性将所有元素全部计算好,还是每一轮计算4个元素来组成子密钥,因为这是可行的,因为每一轮子密钥只后向依赖前一轮子密钥的4个元素。
解密
前文说到,由于AES不是Feistel网络,因此所有层里的操作必须支持完全逆操作。即字节代换层、ShiftRows层和MixColumns层都必须支持逆操作,同时子密钥编排也需要支持逆操作。
密钥加法层逆向
由于密钥加法层只是将输入内容与子密钥进行异或,所以求逆运算只要将计算后的内容再与该轮子密钥进行一次异或,即可得原来的输入。 因为P⊕K⊕K=A。
字节代换层逆向
字节代换层的逆计算也很简单,因为字节代换层使用S-盒支持反向查找。反向S-盒如下表:
ShiftRows层逆向
因为ShiftRows只是简单的向右移位,所逆运算只要相反地左移相应的位即可。
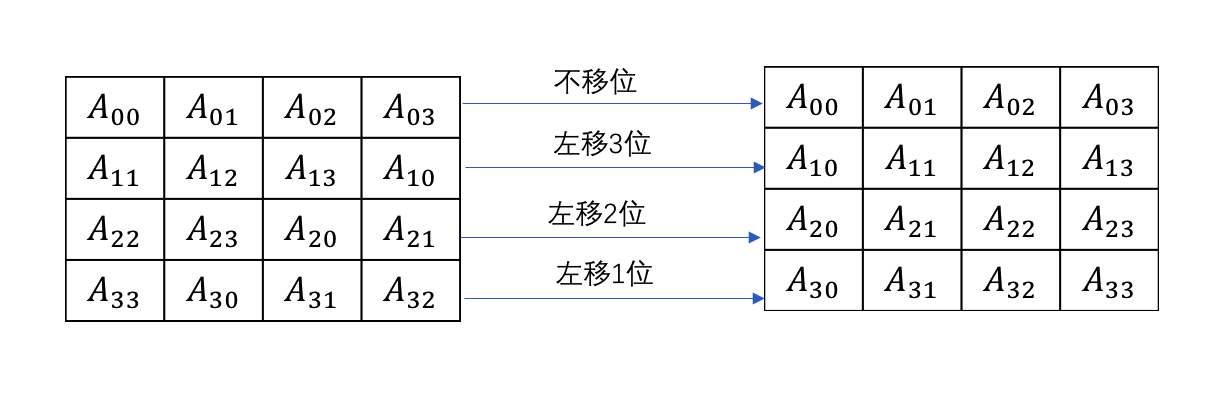
MixColumns层逆向
MixColumns操作是将输入矩阵与一个固定矩阵进行相乘而得到,而根据矩阵运算法则,将结果乘以该固定矩阵的逆矩阵即可还原得到输入内容。
子密钥编排的可逆性
前文说到,AES的每一步计算都是可以进行逆计算的,在每一轮的逆计算过程中,都需要使用与对应轮的子密钥参与解密,只是顺序相反,即第一轮解密需要最后一轮加密的密钥,依次,最后一轮解密需要第一轮加密的密钥。由此可知,只需要在解密前重新按密钥编排算法将所有轮次的子密钥计算得到,在解密时获取相应轮次的密钥即可。只是由于需要先计算好所有轮次的子密钥,而不能像加密那样动态地计算子密钥。
分组加密及其模式与安全性探讨
前文所介绍的DES、AES均通过将明文按照固定长度进行分组后加密,一个明文通常包含多个分组,需要有一个的方法将这些独立的分组加密组合成整个明文的加密密文作为输出,并保证安全。主流的分组加密提供了多种加密模式,本文主要介绍两种主流的操作模式:电子密码本模式(ECB)、密码分组链接模式(CFB)。
电子密码本模式(ECB)
电子密码本模式是最简单的分组加密操作模式,该模式采取将明文按算法要求分割成固定长度的组,如果明文不是固定长度的整数倍,则在加密前将不足长度的组填充固定值,使所有分组的长度均为固定长度,接下来分别对所有分组进行加密,最后将分组的密文组合成密文作为输出。以AES为例:
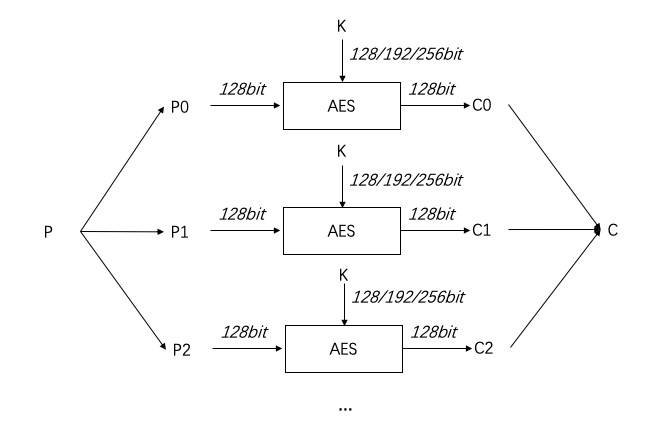
电子密码本模式由于各个分组间的加密可以独立进行,所以拥有很多优点。加密方和解密方之间的同步不是必须的,加密方完成一个分组的加密就可以传输给解密方进行加密,如果传输过程中出现部分分组密文的信息传输错误,只用重发必要的分组密文即可,解密方收到每个分组也可以独立开始解密,而不用等整个密文传输完成后才开始解密。加解密都可以可以并行执行,尤其是在多核的情况下,显著提升加密计算的性能。
但是电子密码本模式也存在一些安全缺陷,一个最大的问题是只要密钥不变,相同的明文分组总是产生相同的分组。利用这个特性,攻击者最容易的攻击方式一种代换攻击,一种是统计信息分析。
所谓代换攻击,即攻击者可以观测经过ECB模式加密的的不同分组,从中判断出每个分组的具体含义,从而针对有攻击必要的分组进行替换,比如有一条经过分组加密的转账信息,它总共包含三个分组,分别如下:

攻击者能通过线路传输漏洞,能监听和修改该信息。攻击者先两次用自己的账号进行转账,先从A账号转账1美元到B账号,再从B账号转账到A账号2美元,通过观察两次转账的密文信息,即可分别出哪个分组是转账账号,哪个分组是入账账号,以及自己的账号的密文分组是什么。攻击者再通过监听其他人的转账信息,然后将自己账号的密文分组替换到其他人转账信息的入账账号里,在交易没有进行消息完整性校验的情况下,攻击就能完成代换攻击。
统计信息泄露也是基于相同的明文总是映射到相同的密文,比如有以下位图信息加密,通过用AES的ECB模式加密后,其结果还是可能通过人眼可以辨识。对于其他更复杂的信息加密,也难逃统计学家的眼睛。再举个例子,比如监察部门要对某些“非法”的访问流量进行识别,也完全可以基于这种特定的统计分析形式,再有大量样本流量的情况下,完全可以借助机器学习甚至深度学习的方式来构建模型进行识别。

密码分组链接模式(CBC)
前文说到电子密码本模式(ECB)存在分组信息特定的缺点,而密码分组链接模式(CBC)针对此缺点给出了解决方案。密码分组链接模式(CBC)主要基于两种设计思想:
- 所有分组间的加密相互链接,即让某个密文分组的结果不只依赖当前的明文分组,还依赖当前分组前的所有分组
- 加密过程中使用初始化向量(Initialization Vector,IV)提供随机化加密能力
密码分组链接模式(CBC)加解密过程大概如下:
- 随机一个初始化向量(IV)值
- 加密第一个分组:$$ y_1=E(x_1 \bigoplus IV) $$,即第一个明文与IV异或后进行加密,得第一个密文分组
- 加密其他分组:$$ y_1=E(xi \bigoplus y{i-1}),i \geq 2 $$
- 解密第一个分组:$$ x_1=D(y_1) \bigoplus IV $$,即第一个密文分组进行解密后再与IV异或,得第一个明文分组
- 解密其他分组:$$ x_i=D(yi)\bigoplus y{i-1} $$
密码分组链接模式(CBC)要求每次加密都选择一个新的IV,通过这个随机的IV设定,提供了一个概率加密方案,可以很好地应对前文说的统计分析攻击,同时IV可以不用保密,可以直接以明文形式传递给解密者,重要的是IV设置要有充分的随机性。只要IV具有充分的随机性,代换攻击在此处也难以发挥的余地,因为攻击构建的相同明文信息无法得到相同的密文分组,也就无法从密文识别出任何模式。
但是CBC模式也是优代价的,因为每个密文的分组计算都依赖前一个密文的分组,所以无法进行并行的加解密计算,当出现某一密文分组的传输错误后,其后面的密文分组可能都无法解密,加解密均无法独立地并行执行。
公钥加密
TBD
Hash函数
TBD
消息验证(MAC)
TBD
HTTPS应用概要
TBD
文章作者 justin huang
上次更新 2018-09-22