Jarvis异步任务平台介绍
文章目录
概述
异步任务是日常开发过程中经常要面对的开发场景,比如系统间数据同步、批量数据加工或验证类资源消耗性任务、大批量数据Excel\CSV文件生成、定时消息通知等等,对于这些场景开发,有很多方式可以实现,如数据库的定时Job、Linux Crontab、Quartz等,但这些方式只是实现了任务的定时触发,对于任务的管理监控、资源调度、复用和可扩展等功能,均不能很好的满足。
Jarvis异步任务平台(Jarvis-Task)是一个基于分布式的定时任务调度方案,它基于主从架构,致力于解决以下问题:
- 循环任务与用户提交形任务定时调度
- 任务执行资源的弹性可扩展
- 可扩展与可并行执行的任务执行框架
- Job配置管理与执行监控
- Built-in常用任务
简介
1、基本概念:
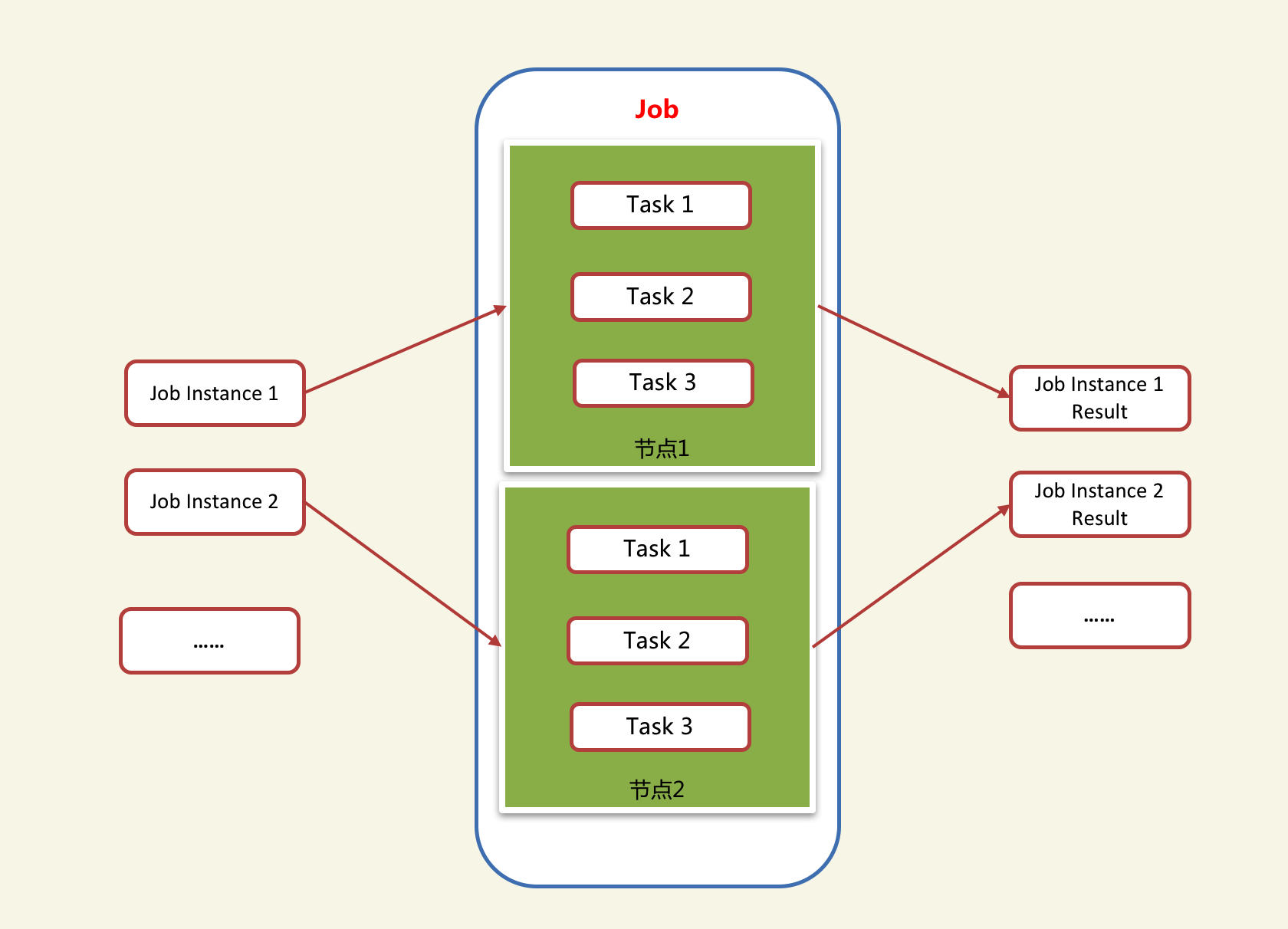
Job:Job是指一个完整的业务逻辑处理作业,一个Job由一个或多个不同的执行单元(Task)组成。Jarvis-Task平台负责Job级别的分布式调度,每个Job的Task之间的调度为单机进程内进行,可进行串行和并行调度。
JobInstance:JobInstance是指Job执行的每一个执行实例,可以理解为Job执行的输入参数,一个Job可以有多个JobInstance,并可以在不同的Job节点中执行。JobInstance分为单次执行实例和循环执行实例,单次执行实例适用于用户提交形的任务,循环执行实例适合于常见的定时循环任务。
分片:一个分片是指一个将一个执行实例按一定的维度分成多个更小的执行单元(Sharding),每个Sharding可以在调度到不同的执行节点上,达到了在多个节点上并行执行一个执行实例的效果,提升任务执行的效率。如一个JobInstance需要处理1000笔数据,有两个执行节点,采取分片的方式,可以分成两个分片,并行执行,每个节点上执行500笔。
节点:即一个执行单元,每个执行单元可以承载多个Job的执行。
2、架构说明
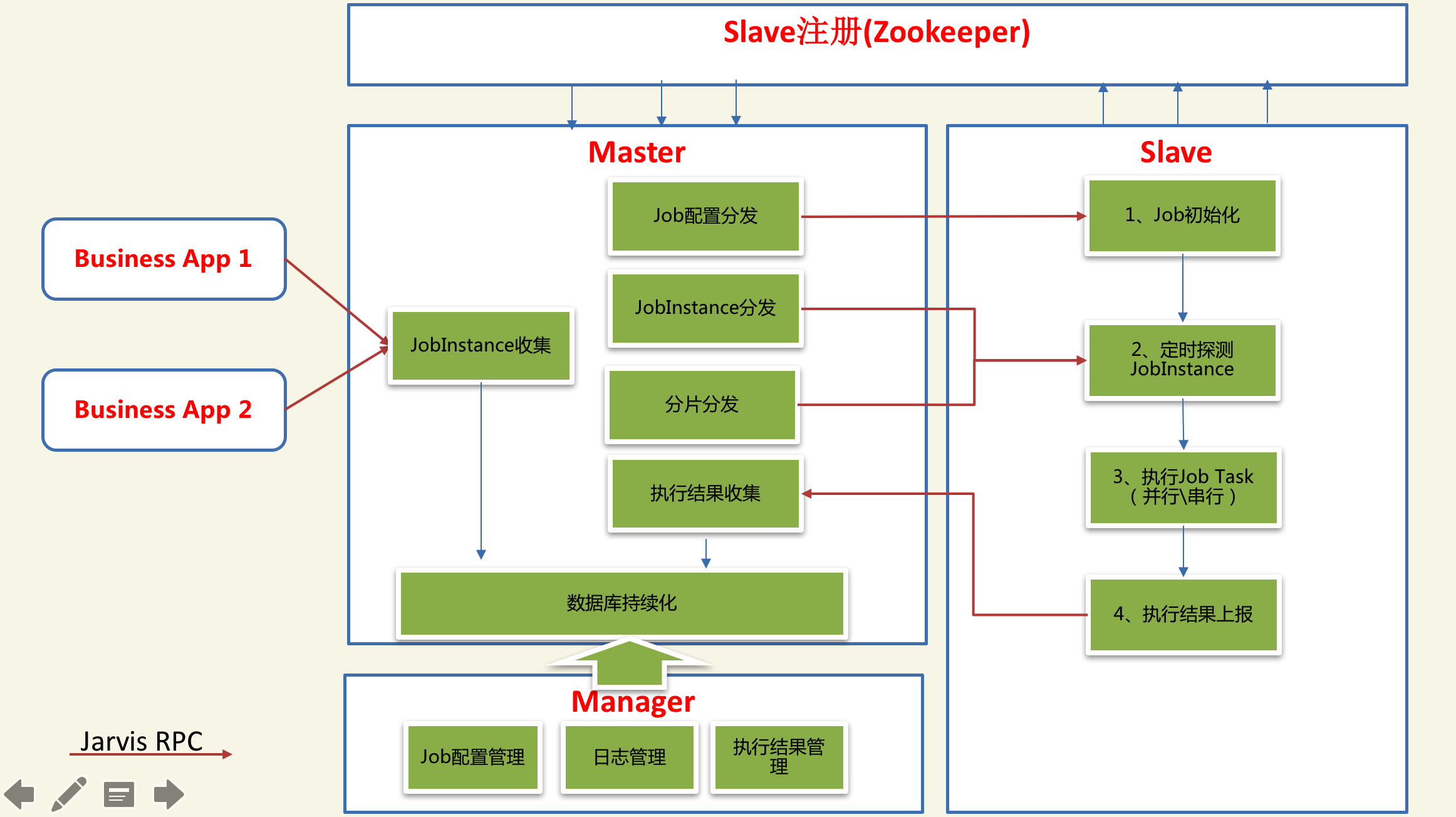
Jarvis-Task采用主从架构(Master-Slave),Master主要负责Job的配置与分发、JobInstance的收集与分发,Job执行结果的收集与监控、Job分片的分发管理等。Slave为实际的Job执行节点,它主要负责Job的定时触发、JobInstance探测与执行、执行结果上报等。Master与Slave均采用多节点设计,两者之间基于Jarvis RPC进行通信与服务发现管理。
如下图所示:
3、分布式调度
Jarvis-Task的Job执行不由Master统一触发,而由各个Job执行节点(Slave)按配置定时触发,以降低了Job调度的复杂性,提高了调度的可靠性,并同时保证了Master的无状态,使Master也可以灵活扩容,保证高可用。Job调度的最小单位是一个JobInstance分片或一个JobInstance,各个Job执行节点采取竞争的方式从Matser获取响应的JobInstance或分片。
4、Job Task调度:
一个Task是Job在一个Job节点上最小的逻辑执行单元,一个Job可以按业务需要拆分为多个Task,按照一定的要求组合成一个完整的执行过程。通过配置,Task之间可以串行或并行进行调度,并提供了前置任务检查的配置,即可以达到多个并行的Task按照一定的前置执行要求进行调度。比如某个Job有A、B、C、D四个个不同的Task,其中A、B、C可以并行执行,但是D需要等待C执行完成才能执行,通过配置任务的前置任务即可满足调度要求。
5、分片管理:
Javis-Task并不是提供自动的Job数据分片功能,而是按照当前配置以及当前Job的活动执行节点个数,均衡地生成分片参数,在Task的业务逻辑开发过程中,可以获取到当前分配的分片参数,在Task的逻辑里自行实现分片参数与真实业务数据间的关系。举例来说:一个Task需要从数据库的某一个表里读取数据进行处理,通过配置,按id进行将数据分为3个分片,分别为0-10w、10w-20w、大于20w,当任务执行是,平台会按照当前可用的Job节点数将3个分片以分片参数的方式分配到相应的节点上,每个节点按照分配到的相应分片参数,获取对应区间范围的参数进行处理,简单来说,Task里获取数据的语句可以用以下方式表示:
select * from table
where id>{minShardingValue}
and (id<{maxShardingValue} or {maxShardingValue} is null)
--其中minShardingValue、maxShardingValue为平台分配的分片参数。
开发入门
1、引入依赖
<dependency>
<groupId>com.tencent.oa.fm</groupId>
<artifactId>jarvis-task-slave</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
2、开发一个简单Task
public class DemoTask extends AbstractTaskBase {
@Override
protected void actualExecute(TaskContext taskContext) throws JobInvokeException {
//从当前执行实例里获取执行参数
String batchId=taskContext.getJobInstanceParamResolver().resolve("batchId");
if(taskContext.getSharding()!=null){
//按分片参数处理数据
int min=taskContext.getSharding().getBeginShardingValue();
int max=taskContext.getSharding().getBeginShardingValue();
List<Data> data=repo.qeury("select * from table where batchId=? and id>? and id<?",batchId,min,max);
Object result= processData(data);
//将结果写回上下文,下一步Task可以获取到
taskContext.put("result",result);
}else{
List<Data> data=repo.qeury("select * from table where batchId=?",batchId);
Object result= processData(data);
taskContext.put("result",result);
}
}
}
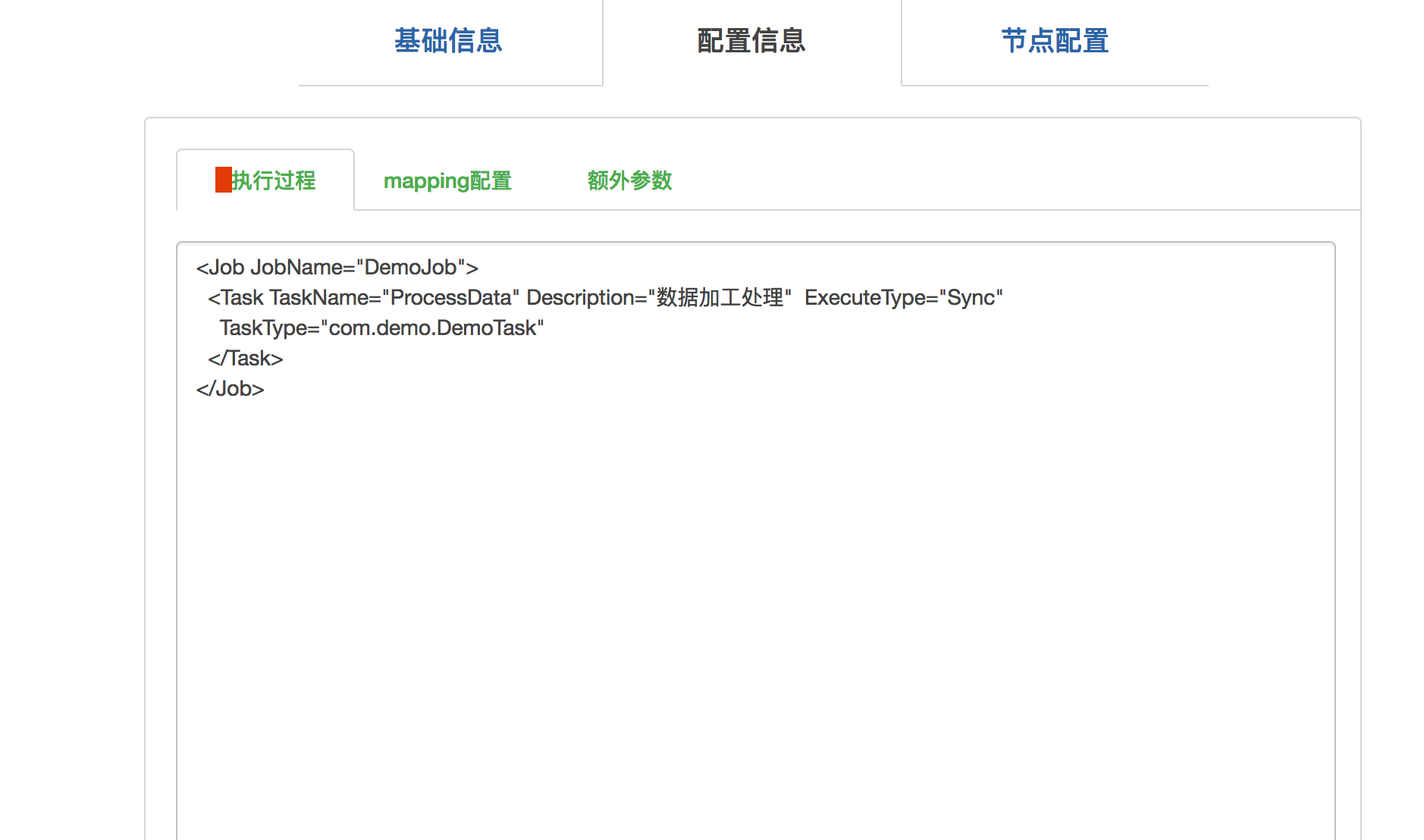
3、配置JobTask
<Job JobName="DemoJob">
<Task TaskName="ProcessData" Description="数据加工处理" ExecuteType="Sync"
TaskType="com.demo.DemoTask"
</Task>
</Job>
一个复杂一点JobTask配置例子: Task2在Task1执行完后串行执行、 Task3、Task4和Task1可以并行执行,但是Task3需要Task1执行成功后才可以执行
<Job JobName="DemoJob">
<Task TaskName="Task1" Description="数据处理1" ExecuteType="Asyn" TaskType="com.demo.DemoTask1"
<Task TaskName="Task2" Description="数据处理2" TaskType="com.demo.DemoTask1"/>
</Task>
<Task TaskName="Task3" Description="数据处理3" ExecuteType="Asyn" TaskType="com.demo.DemoTask3" PreConstraint="ProcessData1"/>
<Task TaskName="Task4" Description="数据处理4" ExecuteType="Asyn" TaskType="com.demo.DemoTask3"/>
</Job>
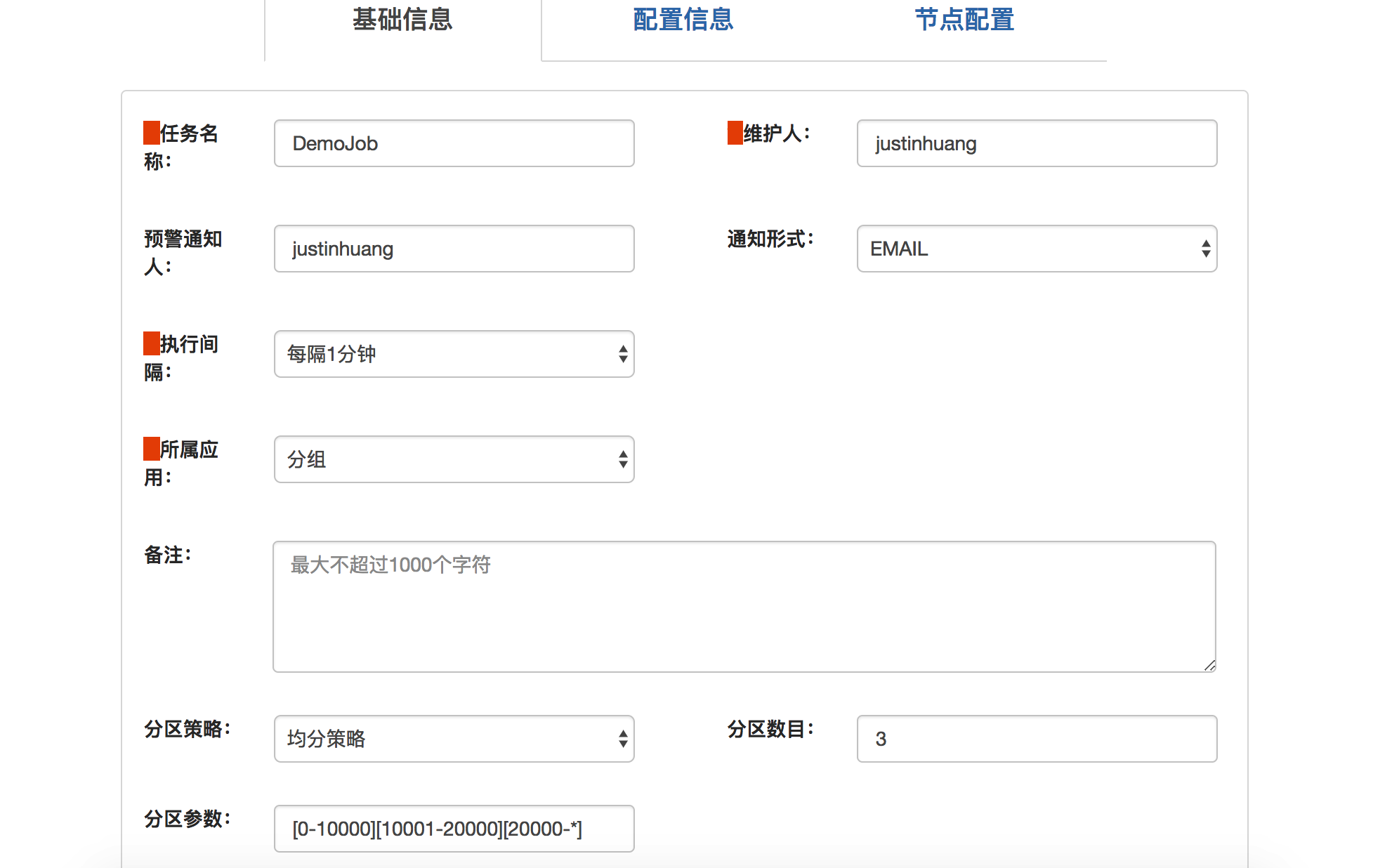
4、在管理端配置Job和分配节点
5、Built-in常用任务介绍
为了提供快速的任务开发以及标准功能复用,平台内置实现了多种Task,如数据库调用、HTTP调用、Jarvis RPC调用、消息发送、Excel\CSV文件生成等常用功能,使得这些任务代码不需要再重新开发,只需要进行配置即可完成相应的业务功能,显著提高了开发效率。需要特别告知的是,Jarvis-Task还提供了一个较为完整用于数据处理的ETL任务库,封装了常见的ETL功能,关于这个ETL库的介绍,将在后续详细说明。
将来规划
1、Job隔离:由于同一个Slave节点上需要执行多个Job,意味着不同Job的代码需要部署在一个节点上,Job间代码依赖的差异,容易导致冲突,从而需要一套代码隔离运行的机制。将来可以考虑采用Docker或模块化加载的方式来实现隔离,目前建议按相应的业务模块部署节点,即尽量将同一个业务模块的Job部署为一个节点,减少依赖差异带来的问题。
2、执行失败转移:目前的设计,当一个JobInstance或一个分片执行失败后,考虑到数据一致性的问题,并不会自动将该JobInstance置位可继续执行。将来需要有一定的机制对执行失败进行分级处理,对非影响业务数据一致性的错误,要能实现自动的错误转移。
3、对于用户提交形的JobInstance,考虑实现自动触发执行,而非目前轮询的方式,以减少由轮询带来的执行时间消耗,实现类似消息队列的方式。
3、完善日志分析功能,依赖于Jarvis的日志分析平台建设进度,更透明化地将Job日志进行分析,发现Job执行过程中的问题。
文章作者 justin huang
上次更新 2018-04-02