RPC服务追踪的原理与实践
文章目录
在分布式服务化架构下,由于分布式服务间存在相互依赖,彼此协同来完成各类业务场景。下图是一个典型的业务场景,从前端发起一个请求,到最后的业务完成,需要经过很多环节,这些环节可能都是分布式服务的方式提供,部署在不同的服务器上进行。而在这种复杂的分布式服务场景下,为了定位问题、性能瓶颈查询、异常日志跟踪等,如果没有服务追踪和分析工具的帮助,都是非常困难的。
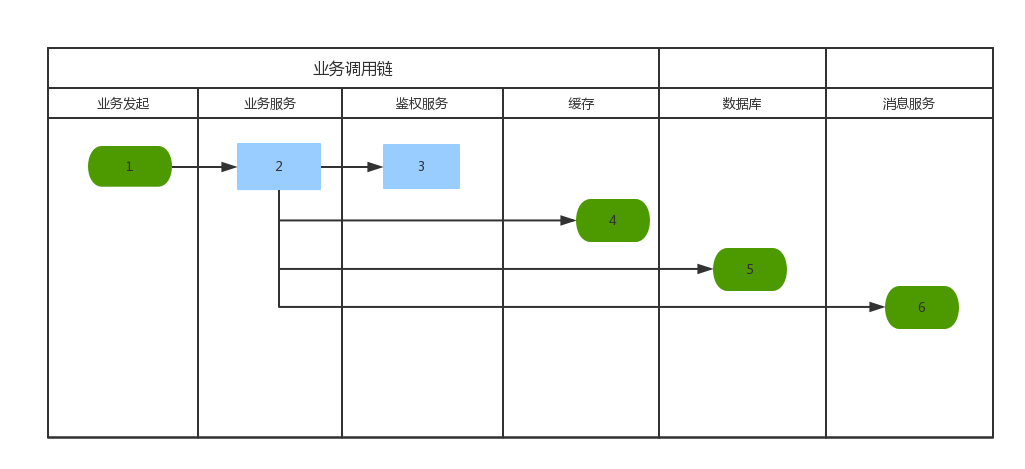
说到分布式追踪,当然不得不提Google为其基于日志的分布式跟踪系统Dapper发表的[论文],在这边论文里,Google介绍了他们在分布式追踪领域的经验,总体来看其核心概念有三个:
- TraceID:用来标识每一条业务请求链的唯一ID,TraceID需要在整个调用链路上传递**
- Span:请求链中的每一个环节为一个Span,每一个Span有一个SpanId来标识,前后Span间形成父子关系**
- Annotation:业务自定义的埋点信息,可以是sql、用户ID等关键信息**
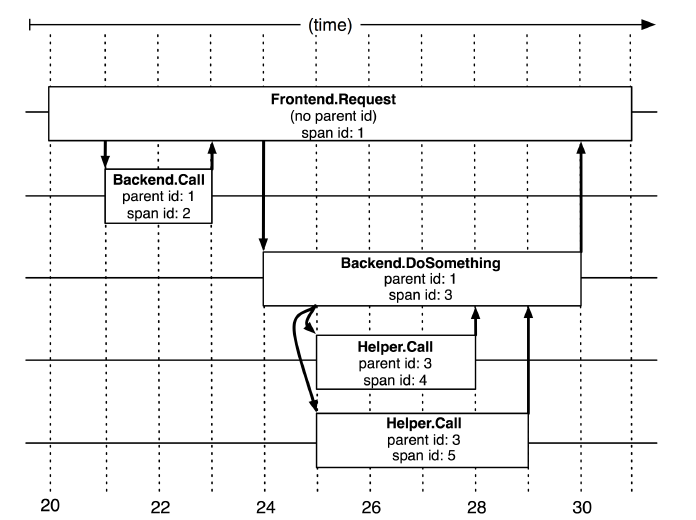 图:5个span在Dapper跟踪树中的关联关系(图来自google论文)
图:5个span在Dapper跟踪树中的关联关系(图来自google论文)
Google论文出来后,业界出现了很多基于其思想实现的开源框架,如Twitter的zipkin,其中zipkin是严格按照来Dapper论文来设计的,他提供了完整的跟踪记录收集、存储功能,以及查询API与界面。其存储支持多种数据库:MySql、ElasticSearch、Cassandra、Redis等等,收集API支持HTTP和Thrift。
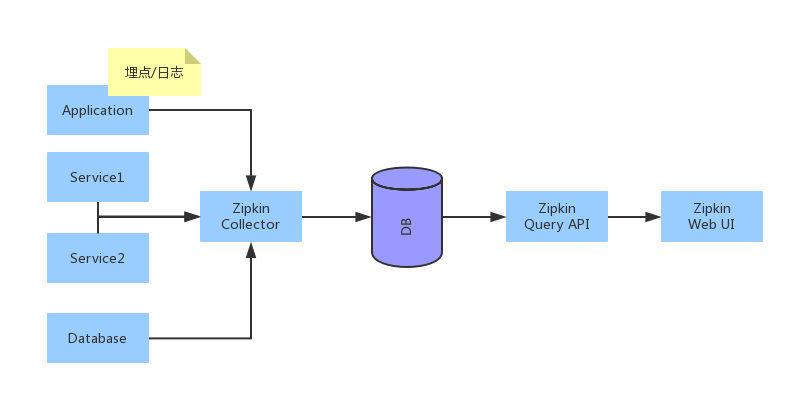
但作为服务跟踪中最难处理的一环,即跟踪埋点,zipkin并没有提供,需要使用方自己实现。业界也有Brave这样的开源项目可以使用,但是评估过后,发现Brave的实现过于复杂,依赖组件也过多,并且其实现的组件更多是支持HTTP服务的调用,对于我们的Thrift RPC服务不能支持,所以没有使用Brave,改为自己实现。自己实现服务埋点和追踪有几个问题需要解决:
TraceID生成
由于要唯一标示每一次调用,所以TraceID需要保证全局唯一。唯一的ID,第一个想到的当然是使用UUID,UUID是一个较为高效又使用方便的唯一ID生成方式,但问题是,zipkin要求TraceID是int64类型,不能是字符串,同时,UUID还有一个问题是不能保证单调有序。对此,有两个架构方案可选:
使用数据库自增长ID来生成,同时需要解决以下问题:
- 性能上,如果每次请求都访问数据库一次,会带来较大的性能损失,所以需要在客户端缓存一个区间的数字,当这个区间的数字不够时再从数据库获取。
- 出于安全要求不能跟数据库直连的客户端不适合,如Web服务器。可以考虑使用一个中间服务作为ID分发。 结合上面两点要求,架构方案如下:
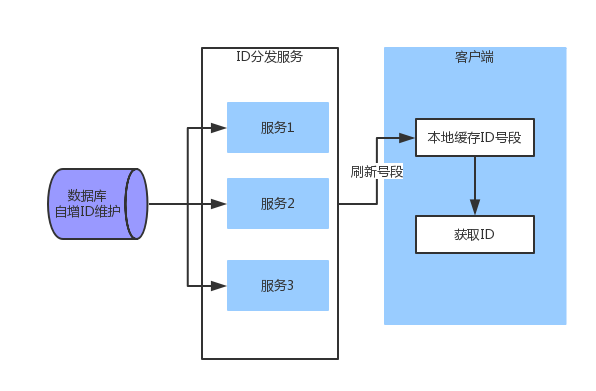
此方案中,ID分发服务的高可用性要求很高,如果该服务出现不可用,将影响到所有服务均不可用,增加了后续运营维护的麻烦。
采用分机器(进程)的方式,保证机器间(进程间)ID不冲突,同时保证单机器(进程)内ID是递增不重复的。这种方式的最大好处时不需要中心化的节点进行ID分发,省掉了系统间的依赖。对于此种方案,最常用的算法是Twitter-Snowflake算法,也是我们最终选择的算法。Snowflake核心思想是将int64的除第一位外的其他63位分成三段,前面41位为时间戳、后面10位为工作机器(进程)ID,也称为WorkerID ,最后12位为递增序列号。
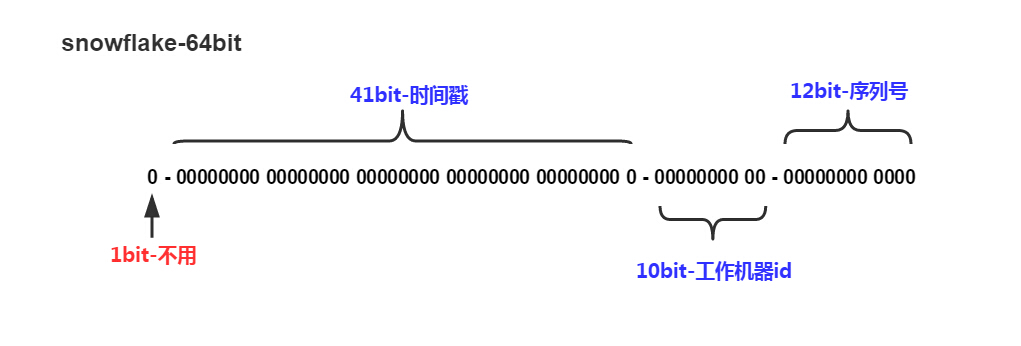
当然,以上长度分段只是默认,可以根据实际情况进行区分,比如41位的时间戳,最长可以用
(-1L ^ -1L<<41)/(3600 * 24 * 365 * 1000)=69年
10位的WorkerID最多支持1023台机器(进程),12位为递增序列表示每毫秒最多4095个ID,在实际中,我们为了支持更多的机器(进程),采取了16位WorkerID,4位标识序列号,即最多支持65535台机器(进程),每毫秒最多生成15个ID。该方案中,WrokerID的分配是需要特别注意的,WorkerID应该每个进程唯一,不能相同,如果相同的话就会出现低概率的ID重复。
分配WorkerID最简单的办法是采取配置的方式,将WorkerID配置到程序的配置文件,但这种方式运营部署起来很麻烦,也容易沟通不到位,导致配置错误或重复。所以我们采取了通过Zookeeper动态分配WorkerID的方案,即在程序启动时,向Zookeeper发起请求,找到一个可用的WorkerID,如果找到一个可用的WorkerID,即创建一个临时子节点,利用Zookeeper临时节点可以自动释放的特性,当程序关闭时,该WorkerID就自动释放了,以达到了WorkerID的重用。只在进程启动时,访问一次Zookeeper来获取WorkeID,所以运行时不需要Zookeeper持续提供服务,性能也不会有损失。
数据埋点
所谓数据埋点,即将跟踪信息(TraceID、Span信息等)写入服务调用的上下文中,如果这个交给业务代码来完成的话,会导致业务代码变得冗余,同时如果业务代码忘记埋点,那就会丢失跟踪信息,所以在底层框架提供数据埋点,非常有必要。 数据埋点主要包括四个阶段:
- Client Send:客户端发起请求时,如果当前线程上下文已经有Trace信息,继续透传当前Trace信息,如果没有,表示一个信息的请求,生成信息的Trace信息进行传递。
- Server Recieve: 服务端接收到请求时间点,此时从当前请求里获取Trace信息,并将当前信息存入线程上下文。
- Server Send:服务端处理业务完成,准备返回响应时,标记业务处理完成,同时将当前Trace信息提交归档。
- Client Receive:客户端接收到服务端响应时,标记服务调用完成,同时将当前Trace信息提交归档。
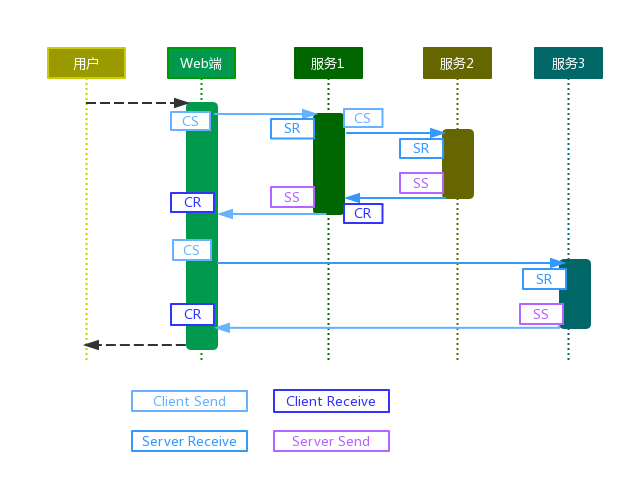
如下的流程示例图说明各阶段埋点的位置,其中CS、SR为发起创建Trace信息到当前线程上下文的位置,CR、SS为归档提交Trace信息的位置。
以上解释了在什么地方埋点和收集Trace信息,但是如何将当前上下文中的信息进行临时存储,并保证线程安全呢?这一点可以借助ThreadLocal来完成,发起创建Trace信息时,往ThreadLocal中写入记录,当前请求过程中再发起新的请求时,从ThreadLocal中获取Trace信息继续往下传递,等信息可以提交归档的时候,从ThreadLocal读取,并清除ThreadLocal中的信息。但是有一个问题需要注意,当发起异步请求时,发起请求的线程和最终被服务响应锁唤起的线程不是同一个线程,对于这种情况,如果响应线程是可由当前线程创建,使用可继承InheritableThreadLocal即可,如果不是,如由线程池来创建,则需要实现特别的线程池管理。另外还有一个办法就是,如果异步回调代码是可以注入的,那我们就可以在发起响应回调的时候注入代码即可。我们的RPC Client里就是采取这种方式。
AsyncMethodCallback callback=new AsyncMethodCallback() {
@Override
public void onComplete(Object o) {
if (transport != null) {
closeTransport(url,transport);
}
//注入trace跟踪处理
Tracer.appendSpan(spanInfo);
Tracer.addAannotation(serviceName, url.getIpByInt(), url.getPort(), AnnotationNames.CLIENT_RECV);
Tracer.submitCurrentSpan();
//执行业务回调
resultHandler.onComplete(o);
}
};
同时,这里有个性能优化点需要注意,当Trace信息可以归档提交时,并不是往zipkin中直接写入,因为zipkin的性能有限,同时网络开销也较大,可以采取异步提交zipkin的方式,客户端归档信息后先从上下文往当前内存队列里写入,然后由单独的线程向zipkin提交记录。
Trace信息传递
前文说到,服务追踪的核心是将Trace信息(TraceID、SpanID)在整个调用链上进行传递,而这些类似上下文的信息,一般不适合作为参数置于服务调用方法里进行传递。如果是HTTP调用,我们可以用HTTP Header来传递信息是非常方便的,但是Thrift服务并没有所谓的Header信息可以传递。 通过研究Thrift代码,发现在Thrift的传输协议实现里,服务端读取数据反序列化协议的入口方法是:
public abstract TMessage readMessageBegin() throws TException;
返回的TMessage对象中,有一个name的属性,其存储的是需要调用的服务方法名,比如我们调用:UserService.getUser(1),那这里的name属性值就是“getUser”。既然这里name可以传递一个公用的字符串,那我们自然可以在此进行扩展,在name属性上传递更多信息。将name按一个文本格式协议,组装成一个header信息进行传递。
//读取消息头
TMessage message = iprot.readMessageBegin();
// 提取Header文本
int index = message.name.lastIndexOf(TMultiplexedProtocol.SEPARATOR);
String headersValue = message.name.substring(0, index);
//采取Http Header文本格式传递
Headers headers = Headers.parseHeaders(headersValue);
String traceID = headers.get(Constants.TPROTOCOL_HEADER_TRACE_ID);//arr[1];
String spanID = headers.get(Constants.TPROTOCOL_HEADER_SPAN_ID);//arr[2];
....
//将message.name还原,继续走thrift标准处理流程
int len = headersValue.length() + TMultiplexedProtocol.SEPARATOR.length();
String methodName = message.name.substring(len);
TMessage standardMessage = new TMessage(
methodName,
message.type,
message.seqid
);
actualProcessor.process(new SomeProtocol(standardMessage))
关于此种扩展方式,Thrift标准库为了实现同一个server里host多个服务Processor,也采取了这种方式,只是标准库只扩展了一个ServiceName字段进行传递而已。具体可以参考Thrift标准库的TMultiplexedProtocol 与TMultiplexedProcessor的代码。
总结
本文介绍了从原理到实现上介绍了如何实现RPC服务追踪的细节,其关键基于调用链的概念。但是在实现上为了做到业务开发透明,还要不影响业务性能,还是需要很多谨慎考虑的。同时,我们其实还有很多未尽事宜需要继续优化,如提供安全的、埋点Tarce上下文的线程池,提供其他多种埋点客户端等等。同时,当Trace信息变成海量后,怎么存储这些信息,以及快速分析,从中挖取更多有意义、有价值的信息,将会成为我们新的挑战。
文章作者 justin huang
上次更新 2017-03-09