Go并发编程模式进阶
文章目录
前段时间Google的Sameer Ajmani在Google I/O上做了关于Go的并发模式的介绍。Slides在此,youtube视频在此(注:上述链接均需翻墙)。
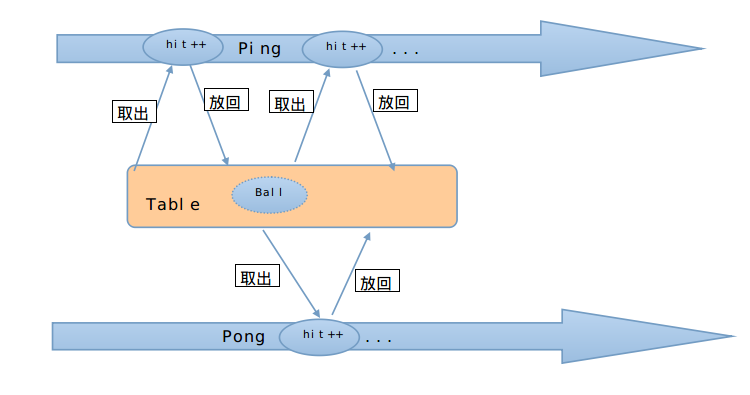
本篇的前提是对goroutine+channel的并发编程模式有基本的了解,建议能读懂下面这个经典ping-pong程序为好。
package main
import (
"fmt"
"time"
)
//定义一个结构
type Ball struct{ hits int }
func main() {
//创建一个可传输Ball的channel
table := make(chan *Ball)
//分别启动ping/pong的goroutine
go Player("Ping", table)
go Player("Pong", table)
//一个Ball进入channel,游戏开始
table <- new(Ball)
//“主”程序暂停1s,等待ping/pong的goroutine执行
time.Sleep(1 * time.Second)
//从channel取出Ball,游戏开始
<-table
//可通过引发异常,显示调用栈的详细信息
//panic("show me the stacks")
}
func Player(name string, table chan *Ball) {
for {
//channel取出Ball,并hits++
ball := <-table
ball.hits++
fmt.Println(name, ball.hits)
//暂停1ms
time.Sleep(1 * time.Millisecond)
//将Ball放回channel
table <- ball
}
}
ping-pong程序的执行过程,可以用下图来表示。
接下来主要说说Go的并发编程里的一些“文艺”使用:如何通信?如何周期性处理事件?如何取消执行?这些高级用法的支持,除了依赖我们上面看到的goroutine+channel外,还要依赖于Go的一个statement:select+case。它可以用来管理和监听多个channel,从而起到“多路复用”的效果。他的基本语法如下。
select {
case xc <- x:
// 向channel(xc)发送一个对象(x)
case y := <-yc:
// 从channel(yc)获取一个对象并赋值到变量(y)
}
下面我们以一个能持续从RSS获取资源项的例子来说明select的使用。 假设我们已经拥有下面这个接口所定义的功能:从一个RSS url获取资源项目(一次调用,获取一次,这个接口的模拟实现,见附1。)
type Fetcher interface {
Fetch() (items []Item, next time.Time, err error)//能从某个rss url获取它的资源项,并能同时返回下一次获取的时间next。
}
`我们用下面这个接口来表示我们希望达到的功能:能从rss url上循环获取资源项,形成资源流的形式;循环获取功能,可以中止。
type Subscription interface {
Updates() <-chan Item//用channel来存放资源,即可实现流的显示
Close() error//关闭获取
}
先看一个这项功能的简单实现,熟悉多线程编程的,应该觉得很眼熟。
type NavieSub struct {
closed bool
err error
updates chan Item
fetcher Fetcher
}
func (s *NavieSub) Close() error {
s.closed = true//设置关闭标识为true
return s.err
}
func (s *NavieSub) Updates() <-chan Item {
return s.updates//返回已经获取的资源项
}
func (s *NavieSub) loop() {//循环获取的方法实现
for {
if s.closed {//判断关闭标识
close(s.updates)//close是内置函数
return
}
items, next, err := s.fetcher.Fetch()//执行一次获取
if err != nil {
s.err = err
time.Sleep(10 * time.Second)
continue//出错时暂停10秒后再开始下次循环
}
for _, item := range items {//将获取的资源项写入,用于返回
s.updates <- item
}
if now := time.Now(); next.After(now) {//暂停到下次获取时间时,再开始下一次获取
time.Sleep(next.Sub(now))
}
}
}
func main() {
fetcher := &FakeFether{channel: "sharecore.info"}
s := &NavieSub{
fetcher: fetcher,
updates: make(chan Item),
}
go s.loop()//启动一个例程执行loop方法(与启动一个线程类似)
time.AfterFunc(3*time.Second, func() {
fmt.Println("closed", s.Close())
})
for item := range s.Updates() {
fmt.Println(item.Channel, item.Title)
}
}
`那以上的简单实现,会有什么问题呢?
首先,明显发现s.err和s.closed的访问是非同步的。
s.closed = true //设置关闭标识为true
if s.closed {//判断关闭标识
close(s.updates) //close是内置函数
return
}
`然后,我们看到s.updates的定义如下:
s := &NavieSub{
fetcher: fetcher,
updates: make(chan Item),//定义为没有buffer的channel,一个channel中同时只能有一个元素
}
`根据上面的定义,s.updates一次只能有一个item进入,当它没有其他goroutine从它里面取出元素时,下面这行代码会发生堵塞。
s.updates <- item
`那以上问题我们有什么办法来避免呢?
对于第一个问题,自然想到的解决办法是加锁,但加锁的方式太不符合Go的“口味”了,同时,加锁的方式,在面对比较复杂的并发场景时,容易导致各类由“锁”引发的问题,这也是线程模型的“恶魔”了。
对于第二个问题,普通的办法时当然是将s.updates定义为一个带buffer的channel。但是buffer定义为多大才合适呢?当取出元素的routine太慢,还是一样可能会导致buffer满了,发生堵塞。
下面,我们来看看如何用一个比较“文艺”的办法来解决上面的问题吧。前面我们提到的select这时可以派上用场了。select的机制实现,差不多可以称为是“事件驱动”的,当然这里的“事件”并不是我们平常其他的事件驱动模型里常看到的I/O,网络请求/响应这样的“事件”,而是监听channel变更的“事件”。
将select与for循环结合起来,可以构造持续监听channel的结构,如下:
func(s *AdvSub) loop(){
//可变状态的定义
for{
//设置不同的channel的监听case
select{
case <-c1:
// 读/写状态
case <-c2:
// 读/写状态
case y:<-c3:
// 读/写状态
}
}
}
我们先来看怎么利用for-select结构来解决第一个close同步的问题:
type AdvSub struct{
closing chan chan error
}
`如上代码所示,我们给sub定义,加了一个“状态”——closing,而我们就可以利用for-select结构来监听从closing的“状态变化”。
`//close方法,
func (s *AdvSub) Close() error{
errc:=make(chan error)
s.closing<-errc
return <-errc
}
var err error//错误状态信息
for{
select{
case errc:=<-s.closing//当Close方法调用时会触发
errc<-err//将错误信息放到Close返回的channel
close(s.updates)
return
}
}
采用这种方式,同步的实现是完全依赖且只依赖于channel的同步机制的,这是可以信赖的。
对于第二个问题,我们可以给sub在加一个状态,比如队列,用来保持它已经获到的资源项。如下代码:
var pending []item//存入新获取的资源(Fetch方法调时),并同时被消费(Update()被调用,取出元素时)
for{
select{
case s.updates<-pending[0]:
pending=pending[1:]//取出后将第一个元素移除,更新状态
}
}
可是你会发现,上面的代码这么修改后并不会如期的正常运行,而是出现如下的错误:
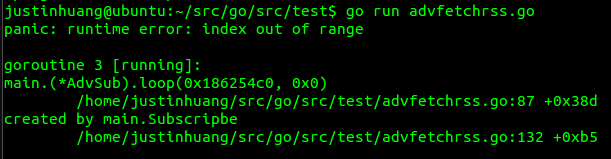
这是因为,一开始pending数组是空的,当执行s.updates<-pending[0]时,会抛出数组越界的异常。 我们可以采取下面的方式来解决这个问题:
var pending []item
for{
var first Item
var updates chan Item
if len(pending) > 0 {
first = pending[0]
updates = s.updates
}
select{
case updates<-first:
pending=pending[1:]
}
}
上面,我们通过for-select结构,解决了同步的问题和堵塞的问题。在NavieSub的loop实现中,我们发现有time.Sleep的调用,对于time.Sleep的模式,我们其实也可以通过for-select结构来解决,这得益于time包下的许多方法/状态,也提供了返回channel的方式来便于监听,比如time.After(duration),time.Ticker等。所以我们就可以方便地将time.Sleep去掉,整合到for-select的结构中来
var pending []Item
var next time.Time
var err error
for{
var fetchDelay time.Duration //下次获取的延迟时间,默认是0(无延迟)
if now:=time.Now();next.After(now){
fetchDelay=next.Sub(now)//计算延迟时间
}
startFetch:=time.After(fetchDelay)//startFetch是一个channnel,时间到达后,会被写入
select {
case startFetch://到达下一次获取时间
var fetched []Item
fetched,next,err=s.fetcher.Fetch()
if err!=nil{
next=time.Now().Add(10*time.Sencond)
break
}
pending=append(pending,fetched...)
}
}
对于以上三种情况,我们总结起来的for-select实现代码就如下:
func (s *AdvSub) loop() {
var err error
var next time.Time
var pending []Item
//综合了三种情况的for-select结构
for {
var fetchDelay time.Duration
if now := time.Now(); next.After(now) {
fetchDelay = next.Sub(now)
}
startFetch := time.After(fetchDelay)
var first Item
var updates chan Item
if len(pending) > 0 {
first = pending[0]
updates = s.updates
}
select {
case errc := <-s.closing://关闭
errc <- err
close(s.updates)
return
case <-startFetch://获取资源
var fetched []Item
fetched, next, err = s.fetcher.Fetch()
if err != nil {
next = time.Now().Add(10 * time.Second)
break
}
pending = append(pending, fetched...)
case updates <- first://取出资源
pending = pending[1:]
}
}
}
最后,分别附上Fetcher接口的模拟实现,以及普通方式和for-select结构方式的完整实现代码。
附1:Fetcher接口的一个实现
type Item struct {
Title, Channel, GUID string
}
type FakeFether struct {
channel string
items []Item
}
func (f *FakeFether) Fetch() (items []Item, next time.Time, err error) {
now := time.Now()
next = now.Add(time.Duration(rand.Intn(5)) * 500 * time.Millisecond)
item := Item{
Channel: f.channel,
Title: fmt.Sprintf("Item %d", len(f.items)),
}
item.GUID = item.Channel + "/" + item.Title
f.items = append(f.items, item)
items = []Item{item}
return
}
##附2:普通方式完整实现
package main
import (
"fmt"
"math/rand"
"time"
)
type Item struct {
Title, Channel, GUID string
}
type Fetcher interface {
Fetch() (tems []Item, next time.Time, err error)
}
type Subscription interface {
Updates() <-chan Item
Close() error
}
type FakeFether struct {
channel string
items []Item
}
func (f *FakeFether) Fetch() (items []Item, next time.Time, err error) {
now := time.Now()
next = now.Add(time.Duration(rand.Intn(5)) * 500 * time.Millisecond)
item := Item{
Channel: f.channel,
Title: fmt.Sprintf("Item %d", len(f.items)),
}
item.GUID = item.Channel + "/" + item.Title
f.items = append(f.items, item)
items = []Item{item}
return
}
type NaiveSub struct {
closed bool
err error
updates chan Item
fetcher Fetcher
}
func (s *NaiveSub) Close() error {
s.closed = true
return s.err
}
func (s *NaiveSub) Updates() <-chan Item {
return s.updates
}
func (s *NaiveSub) loop() {
for {
if s.closed {
close(s.updates)
return
}
items, next, err := s.fetcher.Fetch()
if err != nil {
s.err = err
time.Sleep(10 * time.Second)
continue
}
for _, item := range items {
s.updates <- item
}
if now := time.Now(); next.After(now) {
time.Sleep(next.Sub(now))
}
}
}
type NaiveMerge struct {
subs []Subscription
updates chan Item
}
func (m *NaiveMerge) Close() (err error) {
for _, sub := range m.subs {
if e := sub.Close(); err == nil && e != nil {
err = e
}
}
close(m.updates)
return
}
func (m *NaiveMerge) Updates() <-chan Item {
return m.updates
}
func Merge(subs ...Subscription) Subscription {
m := &NaiveMerge{
subs: subs,
updates: make(chan Item),
}
for _, sub := range subs {
go func(s Subscription) {
for it := range s.Updates() {
m.updates <- it
}
}(sub)
}
return m
}
func Subscripbe(fetcher Fetcher) Subscription {
s := &NaiveSub{
fetcher: fetcher,
updates: make(chan Item),
}
go s.loop()
return s
}
func main() {
fetcher1 := &FakeFether{channel: "sharecore.info"}
fetcher2 := &FakeFether{channel: "blog.golang.org"}
fetcher3 := &FakeFether{channel: "googleblog.blogspot.com"}
fetcher4 := &FakeFether{channel: "googledevelopers.blogspot.com"}
m := Merge(Subscripbe(fetcher1), Subscripbe(fetcher2), Subscripbe(fetcher3), Subscripbe(fetcher4))
time.AfterFunc(3*time.Second, func() {
fmt.Println("closed:", m.Close())
})
for item := range m.Updates() {
fmt.Println(item.Channel, item.Title)
}
panic("show me the stacks")
}
##附3:for-select结构的完整实现
package main
import (
// "errors"
"fmt"
"math/rand"
"time"
)
type Item struct {
Title, Channel, GUID string
}
type Fetcher interface {
Fetch() (tems []Item, next time.Time, err error)
}
type Subscription interface {
Update() <-chan Item
Close() error
}
type FakeFether struct {
channel string
items []Item
}
func (f *FakeFether) Fetch() (items []Item, next time.Time, err error) {
now := time.Now()
next = now.Add(time.Duration(rand.Intn(5)) * 500 * time.Millisecond)
item := Item{
Channel: f.channel,
Title: fmt.Sprintf("Item %d", len(f.items)),
}
item.GUID = item.Channel + "/" + item.Title
f.items = append(f.items, item)
items = []Item{item}
return
}
type AdvSub struct {
closed bool
err error
updates chan Item
fetcher Fetcher
closing chan chan error
}
func (s *AdvSub) Close() error {
errc := make(chan error)
s.closing <- errc
err := <-errc
fmt.Println(err)
return err
}
func (s *AdvSub) Update() <-chan Item {
return s.updates
}
func (s *AdvSub) loop() {
var err error
var next time.Time
var pending []Item
for {
var fetchDelay time.Duration
if now := time.Now(); next.After(now) {
fetchDelay = next.Sub(now)
}
startFetch := time.After(fetchDelay)
var first Item
var updates chan Item
if len(pending) > 0 {
first = pending[0]
updates = s.updates
}
select {
case errc := <-s.closing:
errc <- err
close(s.updates)
return
case <-startFetch:
var fetched []Item
fetched, next, err = s.fetcher.Fetch()
if err != nil {
next = time.Now().Add(10 * time.Second)
break
}
pending = append(pending, fetched...)
case updates <- first:
pending = pending[1:]
}
}
}
type NaiveMerge struct {
subs []Subscription
updates chan Item
}
func (m *NaiveMerge) Close() (err error) {
for _, sub := range m.subs {
if e := sub.Close(); err == nil && e != nil {
err = e
}
}
close(m.updates)
return
}
func (m *NaiveMerge) Update() <-chan Item {
return m.updates
}
func Merge(subs ...Subscription) Subscription {
m := &NaiveMerge{
subs: subs,
updates: make(chan Item),
}
for _, sub := range subs {
go func(s Subscription) {
for it := range s.Update() {
m.updates <- it
}
}(sub)
}
return m
}
func Subscripbe(fetcher Fetcher) Subscription {
s := &AdvSub{
fetcher: fetcher,
updates: make(chan Item),
closing: make(chan chan error),
}
go s.loop()
return s
}
func main() {
fetcher1 := &FakeFether{channel: "sharecore.info"}
fetcher2 := &FakeFether{channel: "blog.golang.org"}
fetcher3 := &FakeFether{channel: "googleblog.blogspot.com"}
fetcher4 := &FakeFether{channel: "googledevelopers.blogspot.com"}
m := Merge(Subscripbe(fetcher1), Subscripbe(fetcher2), Subscripbe(fetcher3), Subscripbe(fetcher4))
time.AfterFunc(3*time.Second, func() {
fmt.Println("closed:", m.Close())
})
for item := range m.Update() {
fmt.Println(item.Channel, item.Title)
}
//panic("show me the stacks")
}
文章作者 justin huang
上次更新 2013-06-10